Tutorial: Use Apache HBase in Azure HDInsight
This tutorial demonstrates how to create an Apache HBase cluster in Azure HDInsight, create HBase tables, and query tables by using Apache Hive. For general HBase information, see HDInsight HBase overview.
In this tutorial, you learn how to:
- Create Apache HBase cluster
- Create HBase tables and insert data
- Use Apache Hive to query Apache HBase
- Use HBase REST APIs using Curl
- Check cluster status
Prerequisites
An SSH client. For more information, see Connect to HDInsight (Apache Hadoop) using SSH.
Bash. The examples in this article use the Bash shell on Windows 10 for the curl commands. See Windows Subsystem for Linux Installation Guide for Windows 10 for installation steps. Other Unix shells will work as well. The curl examples, with some slight modifications, can work on a Windows Command prompt. Or you can use the Windows PowerShell cmdlet Invoke-RestMethod.
Create Apache HBase cluster
The following procedure uses an Azure Resource Manager template to create an HBase cluster. The template also creates the dependent default Azure Storage account. To understand the parameters used in the procedure and other cluster creation methods, see Create Linux-based Hadoop clusters in HDInsight.
Select the following image to open the template in the Azure portal. The template is located in Azure quickstart templates.

From the Custom deployment dialog, enter the following values:
Property Description Subscription Select your Azure subscription that is used to create the cluster. Resource group Create an Azure Resource management group or use an existing one. Location Specify the location of the resource group. ClusterName Enter a name for the HBase cluster. Cluster login name and password The default login name is admin.SSH username and password The default username is sshuser.Other parameters are optional.
Each cluster has an Azure Storage account dependency. After you delete a cluster, the data stays in the storage account. The cluster default storage account name is the cluster name with "store" appended. It's hardcoded in the template variables section.
Select I agree to the terms and conditions stated above, and then select Purchase. It takes about 20 minutes to create a cluster.
After an HBase cluster is deleted, you can create another HBase cluster by using the same default blob container. The new cluster picks up the HBase tables you created in the original cluster. To avoid inconsistencies, we recommend that you disable the HBase tables before you delete the cluster.
Create tables and insert data
You can use SSH to connect to HBase clusters and then use Apache HBase Shell to create HBase tables, insert data, and query data.
For most people, data appears in the tabular format:

In HBase (an implementation of Cloud BigTable), the same data looks like:

To use the HBase shell
Use
sshcommand to connect to your HBase cluster. Edit the command below by replacingCLUSTERNAMEwith the name of your cluster, and then enter the command:ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.netUse
hbase shellcommand to start the HBase interactive shell. Enter the following command in your SSH connection:hbase shellUse
createcommand to create an HBase table with two-column families. The table and column names are case-sensitive. Enter the following command:create 'Contacts', 'Personal', 'Office'Use
listcommand to list all tables in HBase. Enter the following command:listUse
putcommand to insert values at a specified column in a specified row in a particular table. Enter the following commands:put 'Contacts', '1000', 'Personal:Name', 'John Dole' put 'Contacts', '1000', 'Personal:Phone', '1-425-000-0001' put 'Contacts', '1000', 'Office:Phone', '1-425-000-0002' put 'Contacts', '1000', 'Office:Address', '1111 San Gabriel Dr.'Use
scancommand to scan and return theContactstable data. Enter the following command:scan 'Contacts'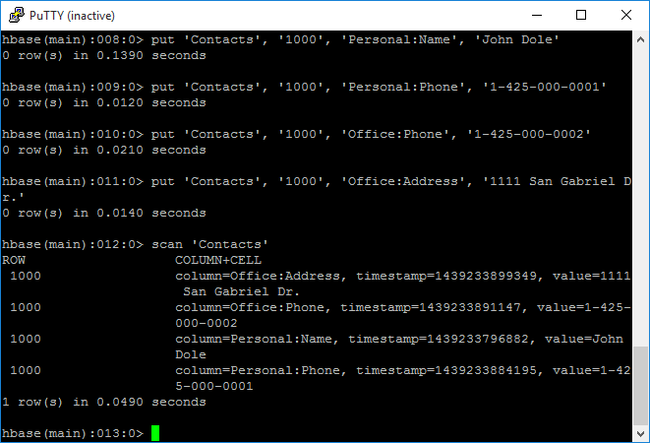
Use
getcommand to fetch contents of a row. Enter the following command:get 'Contacts', '1000'You see similar results as using the
scancommand because there's only one row.For more information about the HBase table schema, see Introduction to Apache HBase Schema Design. For more HBase commands, see Apache HBase reference guide.
Use
exitcommand to stop the HBase interactive shell. Enter the following command:exit
To bulk load data into the contacts HBase table
HBase includes several methods of loading data into tables. For more information, see Bulk loading.
A sample data file can be found in a public blob container, wasb://hbasecontacts@hditutorialdata.blob.core.windows.net/contacts.txt. The content of the data file is:
8396 Calvin Raji 230-555-0191 230-555-0191 5415 San Gabriel Dr.
16600 Karen Wu 646-555-0113 230-555-0192 9265 La Paz
4324 Karl Xie 508-555-0163 230-555-0193 4912 La Vuelta
16891 Jonn Jackson 674-555-0110 230-555-0194 40 Ellis St.
3273 Miguel Miller 397-555-0155 230-555-0195 6696 Anchor Drive
3588 Osa Agbonile 592-555-0152 230-555-0196 1873 Lion Circle
10272 Julia Lee 870-555-0110 230-555-0197 3148 Rose Street
4868 Jose Hayes 599-555-0171 230-555-0198 793 Crawford Street
4761 Caleb Alexander 670-555-0141 230-555-0199 4775 Kentucky Dr.
16443 Terry Chander 998-555-0171 230-555-0200 771 Northridge Drive
You can optionally create a text file and upload the file to your own storage account. For the instructions, see Upload data for Apache Hadoop jobs in HDInsight.
This procedure uses the Contacts HBase table you created in the last procedure.
From your open ssh connection, run the following command to transform the data file to StoreFiles and store at a relative path specified by
Dimporttsv.bulk.output.hbase org.apache.hadoop.hbase.mapreduce.ImportTsv -Dimporttsv.columns="HBASE_ROW_KEY,Personal:Name,Personal:Phone,Office:Phone,Office:Address" -Dimporttsv.bulk.output="/example/data/storeDataFileOutput" Contacts wasb://hbasecontacts@hditutorialdata.blob.core.windows.net/contacts.txtRun the following command to upload the data from
/example/data/storeDataFileOutputto the HBase table:hbase org.apache.hadoop.hbase.mapreduce.LoadIncrementalHFiles /example/data/storeDataFileOutput ContactsYou can open the HBase shell, and use the
scancommand to list the table contents.
Use Apache Hive to query Apache HBase
You can query data in HBase tables by using Apache Hive. In this section, you create a Hive table that maps to the HBase table and uses it to query the data in your HBase table.
From your open ssh connection, use the following command to start Beeline:
beeline -u 'jdbc:hive2://localhost:10001/;transportMode=http' -n adminFor more information about Beeline, see Use Hive with Hadoop in HDInsight with Beeline.
Run the following HiveQL script to create a Hive table that maps to the HBase table. Make sure that you've created the sample table referenced earlier in this article by using the HBase shell before you run this statement.
CREATE EXTERNAL TABLE hbasecontacts(rowkey STRING, name STRING, homephone STRING, officephone STRING, officeaddress STRING) STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' WITH SERDEPROPERTIES ('hbase.columns.mapping' = ':key,Personal:Name,Personal:Phone,Office:Phone,Office:Address') TBLPROPERTIES ('hbase.table.name' = 'Contacts');Run the following HiveQL script to query the data in the HBase table:
SELECT count(rowkey) AS rk_count FROM hbasecontacts;To exit Beeline, use
!exit.To exit your ssh connection, use
exit.
Separate Hive and Hbase Clusters
The Hive query to access HBase data need not be executed from the HBase cluster. Any cluster that comes with Hive (including Spark, Hadoop, HBase, or Interactive Query) can be used to query HBase data, provided the following steps are completed:
- Both clusters must be attached to the same Virtual Network and Subnet
- Copy
/usr/hdp/$(hdp-select --version)/hbase/conf/hbase-site.xmlfrom the HBase cluster headnodes to the Hive cluster headnodes and workernodes.
Secure Clusters
HBase data can also be queried from Hive using ESP-enabled HBase:
- When following a multi-cluster pattern, both clusters must be ESP-enabled.
- To allow Hive to query HBase data, make sure that the
hiveuser is granted permissions to access the HBase data via the Hbase Apache Ranger plugin - When using separate, ESP-enabled clusters, the contents of
/etc/hostsfrom the HBase cluster headnodes must be appended to/etc/hostsof the Hive cluster headnodes and workernodes.
Note
After scaling either clusters, /etc/hosts must be appended again
Use the HBase REST API via Curl
The HBase REST API is secured via basic authentication. You shall always make requests by using Secure HTTP (HTTPS) to help ensure that your credentials are securely sent to the server.
To enable the HBase REST API in the HDInsight cluster, add the following custom startup script to the Script Action section. You can add the startup script when you create the cluster or after the cluster has been created. For Node Type, select Region Servers to ensure that the script executes only in HBase Region Servers.
#! /bin/bash THIS_MACHINE=`hostname` if [[ $THIS_MACHINE != wn* ]] then printf 'Script to be executed only on worker nodes' exit 0 fi RESULT=`pgrep -f RESTServer` if [[ -z $RESULT ]] then echo "Applying mitigation; starting REST Server" sudo python /usr/lib/python2.7/dist-packages/hdinsight_hbrest/HbaseRestAgent.py else echo "REST server already running" exit 0 fiSet environment variable for ease of use. Edit the commands below by replacing
MYPASSWORDwith the cluster login password. ReplaceMYCLUSTERNAMEwith the name of your HBase cluster. Then enter the commands.export PASSWORD='MYPASSWORD' export CLUSTER_NAME=MYCLUSTERNAMEUse the following command to list the existing HBase tables:
curl -u admin:$PASSWORD \ -G https://$CLUSTER_NAME.azurehdinsight.net/hbaserest/Use the following command to create a new HBase table with two-column families:
curl -u admin:$PASSWORD \ -X PUT "https://$CLUSTER_NAME.azurehdinsight.net/hbaserest/Contacts1/schema" \ -H "Accept: application/json" \ -H "Content-Type: application/json" \ -d "{\"@name\":\"Contact1\",\"ColumnSchema\":[{\"name\":\"Personal\"},{\"name\":\"Office\"}]}" \ -vThe schema is provided in the JSon format.
Use the following command to insert some data:
curl -u admin:$PASSWORD \ -X PUT "https://$CLUSTER_NAME.azurehdinsight.net/hbaserest/Contacts1/false-row-key" \ -H "Accept: application/json" \ -H "Content-Type: application/json" \ -d "{\"Row\":[{\"key\":\"MTAwMA==\",\"Cell\": [{\"column\":\"UGVyc29uYWw6TmFtZQ==\", \"$\":\"Sm9obiBEb2xl\"}]}]}" \ -vBase64 encode the values specified in the -d switch. In the example:
MTAwMA==: 1000
UGVyc29uYWw6TmFtZQ==: Personal: Name
Sm9obiBEb2xl: John Dole
false-row-key allows you to insert multiple (batched) values.
Use the following command to get a row:
curl -u admin:$PASSWORD \ GET "https://$CLUSTER_NAME.azurehdinsight.net/hbaserest/Contacts1/1000" \ -H "Accept: application/json" \ -v
For more information about HBase Rest, see Apache HBase Reference Guide.
Note
Thrift is not supported by HBase in HDInsight.
When using Curl or any other REST communication with WebHCat, you must authenticate the requests by providing the user name and password for the HDInsight cluster administrator. You must also use the cluster name as part of the Uniform Resource Identifier (URI) used to send the requests to the server:
curl -u <UserName>:<Password> \
-G https://<ClusterName>.azurehdinsight.net/templeton/v1/status
You should receive a response similar to the following response:
{"status":"ok","version":"v1"}
Check cluster status
HBase in HDInsight ships with a Web UI for monitoring clusters. Using the Web UI, you can request statistics or information about regions.
To access the HBase Master UI
Sign into the Ambari Web UI at
https://CLUSTERNAME.azurehdinsight.netwhereCLUSTERNAMEis the name of your HBase cluster.Select HBase from the left menu.
Select Quick links on the top of the page, point to the active Zookeeper node link, and then select HBase Master UI. The UI is opened in another browser tab:

The HBase Master UI contains the following sections:
- region servers
- backup masters
- tables
- tasks
- software attributes
Cluster recreation
After an HBase cluster is deleted, you can create another HBase cluster by using the same default blob container. The new cluster picks up the HBase tables you created in the original cluster. To avoid inconsistencies, however, we recommend that you disable the HBase tables before you delete the cluster.
You can use the HBase command disable 'Contacts'.
Clean up resources
If you're not going to continue to use this application, delete the HBase cluster that you created with the following steps:
- Sign in to the Azure portal.
- In the Search box at the top, type HDInsight.
- Select HDInsight clusters under Services.
- In the list of HDInsight clusters that appears, click the ... next to the cluster that you created for this tutorial.
- Click Delete. Click Yes.
Next steps
In this tutorial, you learned how to create an Apache HBase cluster. And how to create tables and view the data in those tables from the HBase shell. You also learned how to use a Hive query on data in HBase tables. And how to use the HBase C# REST API to create an HBase table and retrieve data from the table. To learn more, see:
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for