What is Apache Kafka in Azure HDInsight
Apache Kafka is an open-source distributed streaming platform that can be used to build real-time streaming data pipelines and applications. Kafka also provides message broker functionality similar to a message queue, where you can publish and subscribe to named data streams.
The following are specific characteristics of Kafka on HDInsight:
It's a managed service that provides a simplified configuration process. The result is a configuration that is tested and supported by Microsoft.
Microsoft provides a 99.9% Service Level Agreement (SLA) on Kafka uptime. For more information, see the SLA information for HDInsight document.
It uses Azure Managed Disks as the backing store for Kafka. Managed Disks can provide up to 16 TB of storage per Kafka broker. For information on configuring managed disks with Kafka on HDInsight, see Increase scalability of Apache Kafka on HDInsight.
For more information on managed disks, see Azure Managed Disks.
Kafka was designed with a single dimensional view of a rack. Azure separates a rack into two dimensions - Update Domains (UD) and Fault Domains (FD). Microsoft provides tools that rebalance Kafka partitions and replicas across UDs and FDs.
For more information, see High availability with Apache Kafka on HDInsight.
HDInsight allows you to change the number of worker nodes (which host the Kafka-broker) after cluster creation. Upward scaling can be performed from the Azure portal, Azure PowerShell, and other Azure management interfaces. For Kafka, you should rebalance partition replicas after scaling operations. Rebalancing partitions allows Kafka to take advantage of the new number of worker nodes.
HDInsight Kafka does not support downward scaling or decreasing the number of brokers within a cluster. If an attempt is made to decrease the number of nodes, an
InvalidKafkaScaleDownRequestErrorCodeerror is returned.For more information, see High availability with Apache Kafka on HDInsight.
Azure Monitor logs can be used to monitor Kafka on HDInsight. Azure Monitor logs surfaces virtual machine level information, such as disk and NIC metrics, and JMX metrics from Kafka.
For more information, see Analyze logs for Apache Kafka on HDInsight.
Apache Kafka on HDInsight architecture
The following diagram shows a typical Kafka configuration that uses consumer groups, partitioning, and replication to offer parallel reading of events with fault tolerance:
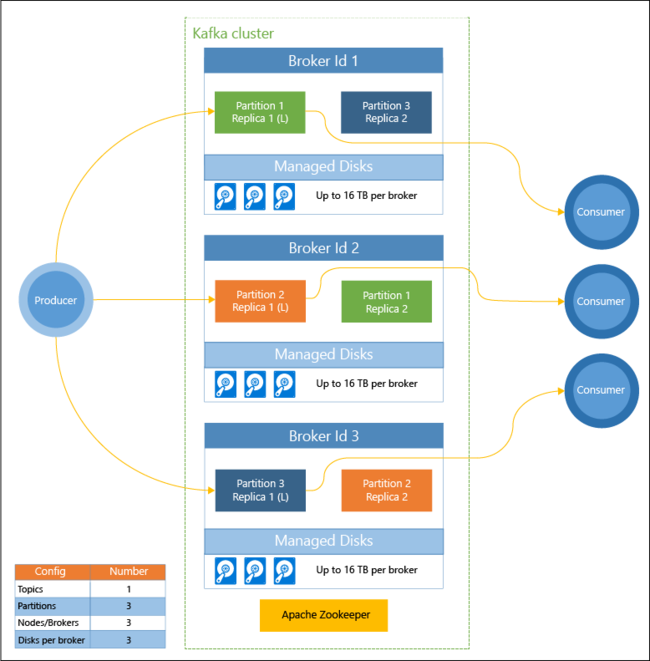
Apache ZooKeeper manages the state of the Kafka cluster. Zookeeper is built for concurrent, resilient, and low-latency transactions.
Kafka stores records (data) in topics. Records are produced by producers, and consumed by consumers. Producers send records to Kafka brokers. Each worker node in your HDInsight cluster is a Kafka broker.
Topics partition records across brokers. When consuming records, you can use up to one consumer per partition to achieve parallel processing of the data.
Replication is employed to duplicate partitions across nodes, protecting against node (broker) outages. A partition denoted with an (L) in the diagram is the leader for the given partition. Producer traffic is routed to the leader of each node, using the state managed by ZooKeeper.
Why use Apache Kafka on HDInsight?
The following are common tasks and patterns that can be performed using Kafka on HDInsight:
| Use | Description |
|---|---|
| Replication of Apache Kafka data | Kafka provides the MirrorMaker utility, which replicates data between Kafka clusters. For information on using MirrorMaker, see Replicate Apache Kafka topics with Apache Kafka on HDInsight. |
| Publish-subscribe messaging pattern | Kafka provides a Producer API for publishing records to a Kafka topic. The Consumer API is used when subscribing to a topic. For more information, see Start with Apache Kafka on HDInsight. |
| Stream processing | Kafka is often used with Spark for real-time stream processing. Kafka 2.1.1 and 2.4.1 (HDInsight version 4.0 and 5.0) support streaming API's that allows you to build streaming solutions without requiring Spark. For more information, see Start with Apache Kafka on HDInsight. |
| Horizontal scale | Kafka partitions streams across the nodes in the HDInsight cluster. Consumer processes can be associated with individual partitions to provide load balancing when consuming records. For more information, see Start with Apache Kafka on HDInsight. |
| In-order delivery | Within each partition, records are stored in the stream in the order that they were received. By associating one consumer process per partition, you can guarantee that records are processed in-order. For more information, see Start with Apache Kafka on HDInsight. |
| Messaging | Since it supports the publish-subscribe message pattern, Kafka is often used as a message broker. |
| Activity tracking | Since Kafka provides in-order logging of records, it can be used to track and re-create activities. For example, user actions on a web site or within an application. |
| Aggregation | Using stream processing, you can aggregate information from different streams to combine and centralize the information into operational data. |
| Transformation | Using stream processing, you can combine and enrich data from multiple input topics into one or more output topics. |
Next steps
Use the following links to learn how to use Apache Kafka on HDInsight:
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for