What is Azure Batch?
Use Azure Batch to run large-scale parallel and high-performance computing (HPC) batch jobs efficiently in Azure. Azure Batch creates and manages a pool of compute nodes (virtual machines), installs the applications you want to run, and schedules jobs to run on the nodes. There's no cluster or job scheduler software to install, manage, or scale. Instead, you use Batch APIs and tools, command-line scripts, or the Azure portal to configure, manage, and monitor your jobs.
Developers can use Batch as a platform service to build SaaS applications or client apps where large-scale execution is required. For example, you can build a service with Batch to run a Monte Carlo risk simulation for a financial services company, or a service to process many images.
There is no additional charge for using Batch. You only pay for the underlying resources consumed, such as the virtual machines, storage, and networking.
For a comparison between Batch and other HPC solution options in Azure, see High Performance Computing (HPC) on Azure.
Run parallel workloads
Batch works well with intrinsically parallel (also known as "embarrassingly parallel") workloads. These workloads have applications which can run independently, with each instance completing part of the work. When the applications are executing, they might access some common data, but they don't communicate with other instances of the application. Intrinsically parallel workloads can therefore run at a large scale, determined by the amount of compute resources available to run applications simultaneously.
Some examples of intrinsically parallel workloads you can bring to Batch:
- Financial risk modeling using Monte Carlo simulations
- VFX and 3D image rendering
- Image analysis and processing
- Media transcoding
- Genetic sequence analysis
- Optical character recognition (OCR)
- Data ingestion, processing, and ETL operations
- Software test execution
You can also use Batch to run tightly coupled workloads, where the applications you run need to communicate with each other, rather than running independently. Tightly coupled applications normally use the Message Passing Interface (MPI) API. You can run your tightly coupled workloads with Batch using Microsoft MPI or Intel MPI. Improve application performance with specialized HPC and GPU-optimized VM sizes.
Some examples of tightly coupled workloads:
- Finite element analysis
- Fluid dynamics
- Multi-node AI training
Many tightly coupled jobs can be run in parallel using Batch. For example, you can perform multiple simulations of a liquid flowing through a pipe with varying pipe widths.
Additional Batch capabilities
Batch supports large-scale rendering workloads with rendering tools including Autodesk Maya, 3ds Max, Arnold, and V-Ray.
You can also run Batch jobs as part of a larger Azure workflow to transform data, managed by tools such as Azure Data Factory.
How it works
A common scenario for Batch involves scaling out intrinsically parallel work, such as the rendering of images for 3D scenes, on a pool of compute nodes. This pool can be your "render farm" that provides tens, hundreds, or even thousands of cores to your rendering job.
The following diagram shows steps in a common Batch workflow, with a client application or hosted service using Batch to run a parallel workload.
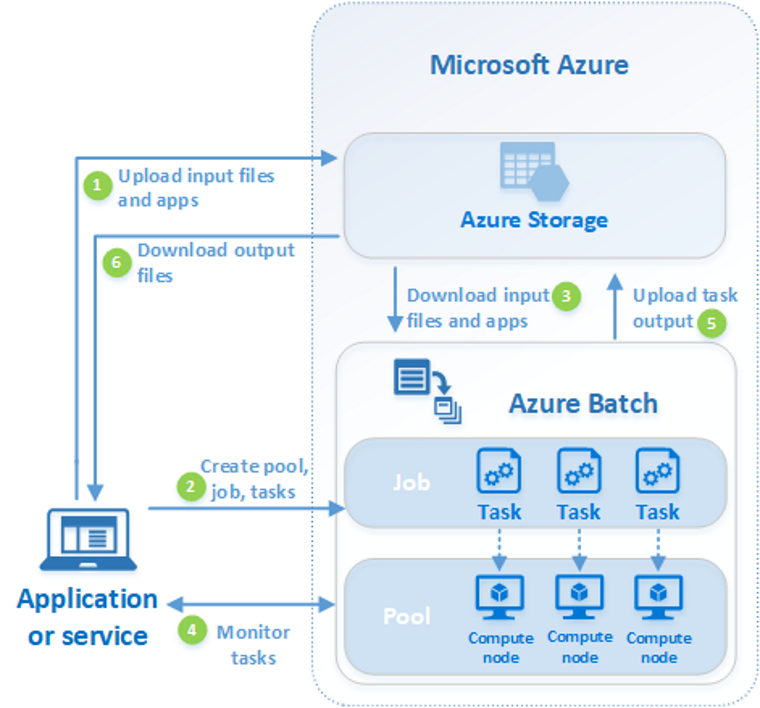
| Step | Description |
|---|---|
| 1. Upload input files and the applications to process those files to your Azure Storage account. | The input files can be any data that your application processes, such as financial modeling data, or video files to be transcoded. The application files can include scripts or applications that process the data, such as a media transcoder. |
| 2. Create a Batch pool of compute nodes in your Batch account, a job to run the workload on the pool, and tasks in the job. | Compute nodes are the VMs that execute your tasks. Specify properties for your pool, such as the number and size of the nodes, a Windows or Linux VM image, and an application to install when the nodes join the pool. Manage the cost and size of the pool by using Azure Spot VMs or by automatically scaling the number of nodes as the workload changes. When you add tasks to a job, the Batch service automatically schedules the tasks for execution on the compute nodes in the pool. Each task uses the application that you uploaded to process the input files. |
| 3. Download input files and the applications to Batch | Before each task executes, it can download the input data that it will process to the assigned node. If the application isn't already installed on the pool nodes, it can be downloaded here instead. When the downloads from Azure Storage complete, the task executes on the assigned node. |
| 4. Monitor task execution | As the tasks run, query Batch to monitor the progress of the job and its tasks. Your client application or service communicates with the Batch service over HTTPS. Because you may be monitoring thousands of tasks running on thousands of compute nodes, be sure to query the Batch service efficiently. |
| 5. Upload task output | As the tasks complete, they can upload their result data to Azure Storage. You can also retrieve files directly from the file system on a compute node. |
| 6. Download output files | When your monitoring detects that the tasks in your job have completed, your client application or service can download the output data for further processing. |
Keep in mind that the workflow described above is just one way to use Batch, and there are many other features and options. For example, you can execute multiple tasks in parallel on each compute node. Or you can use job preparation and completion tasks to prepare the nodes for your jobs, then clean up afterward.
See Batch service workflow and resources for an overview of features such as pools, nodes, jobs, and tasks. Also see the latest Batch service updates.
In-region data residency
Azure Batch does not move or store customer data out of the region in which it is deployed.
Next steps
Get started with Azure Batch with one of these quickstarts:
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for