Business continuity and disaster recovery
Microsoft's Business Application Platform (BAP) provides Business Continuity and Disaster Recovery (BCDR) capabilities to all production type environments in Dynamics 365 and Power Platform SAAS applications. This article describes details and practices Microsoft takes to ensure your production data is resilient during regional outage.
Backup and Replication of Production Environments
Microsoft is dedicated to ensuring the highest service availability levels for your critical applications and data. Microsoft ensures that the baseline infrastructure and platform services are available through its business continuity and disaster recovery architecture by:
Enabling geo redundancy, where in, all data from production environments (excluding Default environments) is backed up to the paired/secondary region. These replicas are referred to as geo-secondary replicas that are set up during the time the primary environment is deployed.
Geo-secondary replicas are kept synchronized with the primary environment through continuous data replication. While at any given point, a secondary region might be slightly behind the primary region, the data on a secondary is guaranteed to be transactionally consistent. For more information on geo replication, visit Active geo-replication - Azure SQL Database
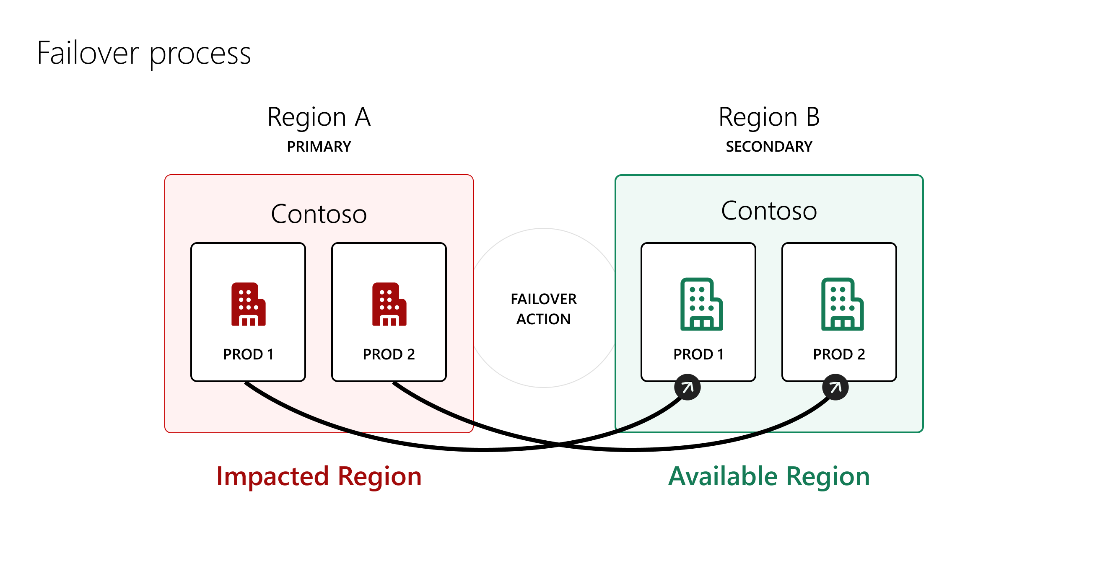
The above illustration shows that when primary Region A gets impacted during an outage, production type environments from Region A failover to secondary Region B, which is healthy. No action is taken on other types of environments such as default, Trial, sandbox, Teams or developer.
To learn more about data protection in nonproduction environments, see Back up and restore environments.
How will you be notified of an Outage?
The primary communications channel is via Service Health Dashboard (SHD) within Microsoft and Power platform admin centers. The Microsoft communications team will initiate the process by posting initial communications to notify you of the outage and post necessary updates to the SHD as needed. For more information on how to view your messages on the admin center, see Home page dashboard. To be better prepared, visit the readiness page.
Failover and Failback processes and criteria for Business continuity
Failover and failback are the two main tasks accomplished during the business continuity and disaster recovery (BCDR) process, the purpose is to minimize the impact of a disaster on the availability and performance of critical business functions and applications.
Failover is the process of switching to a designated geo-secondary replica of all the systems and data from your primary production site. At the completion of failover operation your production environment will be accessible from the geo-secondary site.
Important
While the Finance and Operations apps are operating in the secondary region after a failover maintenance, package deployments, Financial Reporting, and Power BI reporting are unavailable.
Failback operation is the process of returning production to its original location after a disaster or a scheduled maintenance period.
As part of Microsoft's business continuity and disaster recovery (BCDR) standard, customers can be ensured that each online service within Microsoft reviews, tests and updates its BCDR plan annually. The Microsoft Cloud Business Continuity and Disaster Recovery Plan Validation Report is available to customers on Service Trust Portal.
In the event of an unanticipated region-wide outage, such as a natural disaster that affects the entire Azure region, the following are the sequence of steps and processes that will take place.
| Microsoft's responsibility | Customers responsibilities |
|---|---|
| If Microsoft detects an outage and sees customers being impacted, then Microsoft's communication team will send out the necessary communications and keep the Service Health Dashboard up to date with the necessary information. | None |
| If in the event of an outage, Microsoft will perform an automatic failover of the production instances to the secondary region if there is NO DATA LOSS to the customer. | None |
| If in the event of an outage, Microsoft determines that there's DATA LOSS, then failing over the environment isn't initiated without customer consent/approval. | Once the customer is aware of the ongoing outage, and sees IMPACT, then it's the customer's responsibility: - To reach out to Microsoft via support and find out the level of data loss that would occur if a failover is initiated. - If the data loss is at an acceptable level to their organization standards, then customers should provide their consent via support, for Microsoft to initiate a failover. |
| When Microsoft determines that the primary region is back online and is fully operational, a FAILBACK is performed on the production instances. There's no data loss during the planned failback process but users could experience brief interruptions or disconnects during this window. | None |
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for