Model customization (version 4.0 preview)
Model customization lets you train a specialized Image Analysis model for your own use case. Custom models can do either image classification (tags apply to the whole image) or object detection (tags apply to specific areas of the image). Once your custom model is created and trained, it belongs to your Vision resource, and you can call it using the Analyze Image API.
Implement model customization quickly and easily by following a quickstart:
Important
You can train a custom model using either the Custom Vision service or the Image Analysis 4.0 service with model customization. The following table compares the two services.
| Areas | Custom Vision service | Image Analysis 4.0 service | ||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Tasks | Image classification Object detection |
Image classification Object detection |
||||||||||||||||||||||||||||||||||||
| Base model | CNN | Transformer model | ||||||||||||||||||||||||||||||||||||
| Labeling | Customvision.ai | AML Studio | ||||||||||||||||||||||||||||||||||||
| Web Portal | Customvision.ai | Vision Studio | ||||||||||||||||||||||||||||||||||||
| Libraries | REST, SDK | REST, Python Sample | ||||||||||||||||||||||||||||||||||||
| Minimum training data needed | 15 images per category | 2-5 images per category | ||||||||||||||||||||||||||||||||||||
| Training data storage | Uploaded to service | Customer’s blob storage account | ||||||||||||||||||||||||||||||||||||
| Model hosting | Cloud and edge | Cloud hosting only, edge container hosting to come | ||||||||||||||||||||||||||||||||||||
| AI quality |
|
|
||||||||||||||||||||||||||||||||||||
| Pricing | Custom Vision pricing | Image Analysis pricing |
Scenario components
The main components of a model customization system are the training images, COCO file, dataset object, and model object.
Training images
Your set of training images should include several examples of each of the labels you want to detect. You'll also want to collect a few extra images to test your model with once it's trained. The images need to be stored in an Azure Storage container in order to be accessible to the model.
In order to train your model effectively, use images with visual variety. Select images that vary by:
- camera angle
- lighting
- background
- visual style
- individual/grouped subject(s)
- size
- type
Additionally, make sure all of your training images meet the following criteria:
- The image must be presented in JPEG, PNG, GIF, BMP, WEBP, ICO, TIFF, or MPO format.
- The file size of the image must be less than 20 megabytes (MB).
- The dimensions of the image must be greater than 50 x 50 pixels and less than 16,000 x 16,000 pixels.
COCO file
The COCO file references all of the training images and associates them with their labeling information. In the case of object detection, it specified the bounding box coordinates of each tag on each image. This file must be in the COCO format, which is a specific type of JSON file. The COCO file should be stored in the same Azure Storage container as the training images.
Tip
About COCO files
COCO files are JSON files with specific required fields: "images", "annotations", and "categories". A sample COCO file will look like this:
{
"images": [
{
"id": 1,
"width": 500,
"height": 828,
"file_name": "0.jpg",
"absolute_url": "https://blobstorage1.blob.core.windows.net/cpgcontainer/0.jpg"
},
{
"id": 2,
"width": 754,
"height": 832,
"file_name": "1.jpg",
"absolute_url": "https://blobstorage1.blob.core.windows.net/cpgcontainer/1.jpg"
},
...
],
"annotations": [
{
"id": 1,
"category_id": 7,
"image_id": 1,
"area": 0.407,
"bbox": [
0.02663142641129032,
0.40691584277841153,
0.9524163571731749,
0.42766634515266866
]
},
{
"id": 2,
"category_id": 9,
"image_id": 2,
"area": 0.27,
"bbox": [
0.11803319477782331,
0.41586723392402375,
0.7765206955096307,
0.3483334397217212
]
},
...
],
"categories": [
{
"id": 1,
"name": "vegall original mixed vegetables"
},
{
"id": 2,
"name": "Amy's organic soups lentil vegetable"
},
{
"id": 3,
"name": "Arrowhead 8oz"
},
...
]
}
COCO file field reference
If you're generating your own COCO file from scratch, make sure all the required fields are filled with the correct details. The following tables describe each field in a COCO file:
"images"
| Key | Type | Description | Required? |
|---|---|---|---|
id |
integer | Unique image ID, starting from 1 | Yes |
width |
integer | Width of the image in pixels | Yes |
height |
integer | Height of the image in pixels | Yes |
file_name |
string | A unique name for the image | Yes |
absolute_url or coco_url |
string | Image path as an absolute URI to a blob in a blob container. The Vision resource must have permission to read the annotation files and all referenced image files. | Yes |
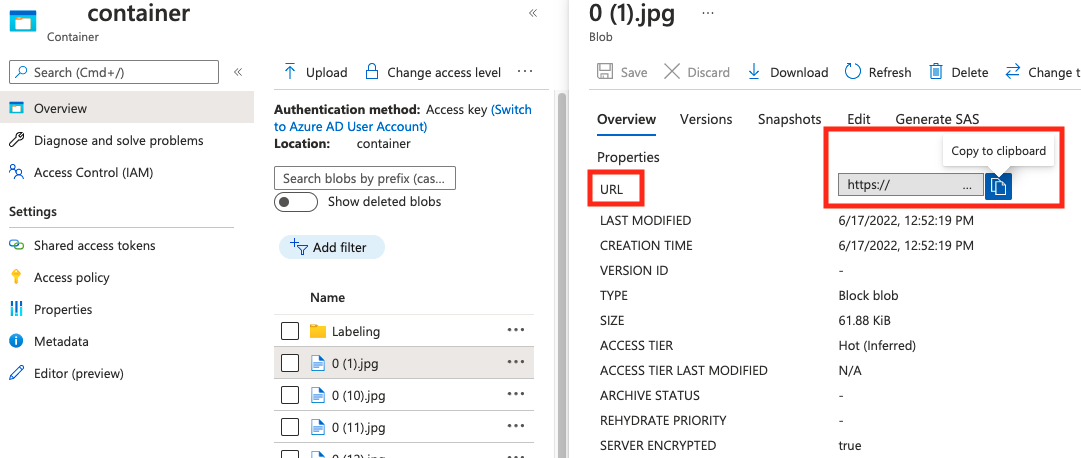
The value for absolute_url can be found in your blob container's properties:
"annotations"
| Key | Type | Description | Required? |
|---|---|---|---|
id |
integer | ID of the annotation | Yes |
category_id |
integer | ID of the category defined in the categories section |
Yes |
image_id |
integer | ID of the image | Yes |
area |
integer | Value of 'Width' x 'Height' (third and fourth values of bbox) |
No |
bbox |
list[float] | Relative coordinates of the bounding box (0 to 1), in the order of 'Left', 'Top', 'Width', 'Height' | Yes |
"categories"
| Key | Type | Description | Required? |
|---|---|---|---|
id |
integer | Unique ID for each category (label class). These should be present in the annotations section. |
Yes |
name |
string | Name of the category (label class) | Yes |
COCO file verification
You can use our Python sample code to check the format of a COCO file.
Dataset object
The Dataset object is a data structure stored by the Image Analysis service that references the association file. You need to create a Dataset object before you can create and train a model.
Model object
The Model object is a data structure stored by the Image Analysis service that represents a custom model. It must be associated with a Dataset in order to do initial training. Once it's trained, you can query your model by entering its name in the model-name query parameter of the Analyze Image API call.
Quota limits
The following table describes the limits on the scale of your custom model projects.
| Category | Generic image classifier | Generic object detector |
|---|---|---|
| Max # training hours | 288 (12 days) | 288 (12 days) |
| Max # training images | 1,000,000 | 200,000 |
| Max # evaluation images | 100,000 | 100,000 |
| Min # training images per category | 2 | 2 |
| Max # tags per image | multiclass: 1 | NA |
| Max # regions per image | NA | 1,000 |
| Max # categories | 2,500 | 1,000 |
| Min # categories | 2 | 1 |
| Max image size (Training) | 20 MB | 20 MB |
| Max image size (Prediction) | Sync: 6 MB, Batch: 20 MB | Sync: 6 MB, Batch: 20 MB |
| Max image width/height (Training) | 10,240 | 10,240 |
| Min image width/height (Prediction) | 50 | 50 |
| Available regions | West US 2, East US, West Europe | West US 2, East US, West Europe |
| Accepted image types | jpg, png, bmp, gif, jpeg | jpg, png, bmp, gif, jpeg |
Frequently asked questions
Why is my COCO file import failing when importing from blob storage?
Currently, Microsoft is addressing an issue that causes COCO file import to fail with large datasets when initiated in Vision Studio. To train using a large dataset, it's recommended to use the REST API instead.
Why does training take longer/shorter than my specified budget?
The specified training budget is the calibrated compute time, not the wall-clock time. Some common reasons for the difference are listed:
Longer than specified budget:
- Image Analysis experiences a high training traffic, and GPU resources may be tight. Your job may wait in the queue or be put on hold during training.
- The backend training process ran into unexpected failures, which resulted in retrying logic. The failed runs don't consume your budget, but this can lead to longer training time in general.
- Your data is stored in a different region than your Vision resource, which will lead to longer data transmission time.
Shorter than specified budget: The following factors speed up training at the cost of using more budget in certain wall-clock time.
- Image Analysis sometimes trains with multiple GPUs depending on your data.
- Image Analysis sometimes trains multiple exploration trials on multiple GPUs at the same time.
- Image Analysis sometimes uses premier (faster) GPU SKUs to train.
Why does my training fail and what I should do?
The following are some common reasons for training failure:
diverged: The training can't learn meaningful things from your data. Some common causes are:- Data is not enough: providing more data should help.
- Data is of poor quality: check if your images are of low resolution, extreme aspect ratios, or if annotations are wrong.
notEnoughBudget: Your specified budget isn't enough for the size of your dataset and model type you're training. Specify a larger budget.datasetCorrupt: Usually this means your provided images aren't accessible or the annotation file is in the wrong format.datasetNotFound: dataset cannot be foundunknown: This could be a backend issue. Reach out to support for investigation.
What metrics are used for evaluating the models?
The following metrics are used:
- Image classification: Average Precision, Accuracy Top 1, Accuracy Top 5
- Object detection: Mean Average Precision @ 30, Mean Average Precision @ 50, Mean Average Precision @ 75
Why does my dataset registration fail?
The API responses should be informative enough. They are:
DatasetAlreadyExists: A dataset with the same name existsDatasetInvalidAnnotationUri: "An invalid URI was provided among the annotation URIs at dataset registration time.
How many images are required for reasonable/good/best model quality?
Although Florence models have great few-shot capability (achieving great model performance under limited data availability), in general more data makes your trained model better and more robust. Some scenarios require little data (like classifying an apple against a banana), but others require more (like detecting 200 kinds of insects in a rainforest). This makes it difficult to give a single recommendation.
If your data labeling budget is constrained, our recommended workflow is to repeat the following steps:
Collect
Nimages per class, whereNimages are easy for you to collect (for example,N=3)Train a model and test it on your evaluation set.
If the model performance is:
- Good enough (performance is better than your expectation or performance close to your previous experiment with less data collected): Stop here and use this model.
- Not good (performance is still below your expectation or better than your previous experiment with less data collected at a reasonable margin):
- Collect more images for each class—a number that's easy for you to collect—and go back to Step 2.
- If you notice the performance is not improving any more after a few iterations, it could be because:
- this problem isn't well defined or is too hard. Reach out to us for case-by-case analysis.
- the training data might be of low quality: check if there are wrong annotations or very low-pixel images.
How much training budget should I specify?
You should specify the upper limit of budget that you're willing to consume. Image Analysis uses an AutoML system in its backend to try out different models and training recipes to find the best model for your use case. The more budget that's given, the higher the chance of finding a better model.
The AutoML system also stops automatically if it concludes there's no need to try more, even if there is still remaining budget. So, it doesn't always exhaust your specified budget. You're guaranteed not to be billed over your specified budget.
Can I control the hyper-parameters or use my own models in training?
No, Image Analysis model customization service uses a low-code AutoML training system that handles hyper-param search and base model selection in the backend.
Can I export my model after training?
The prediction API is only supported through the cloud service.
Why does the evaluation fail for my object detection model?
Below are the possible reasons:
internalServerError: An unknown error occurred. Please try again later.modelNotFound: The specified model was not found.datasetNotFound: The specified dataset was not found.datasetAnnotationsInvalid: An error occurred while trying to download or parse the ground truth annotations associated with the test dataset.datasetEmpty: The test dataset did not contain any "ground truth" annotations.
What is the expected latency for predictions with custom models?
We do not recommend you use custom models for business critical environments due to potential high latency. When customers train custom models in Vision Studio, those custom models belong to the Azure AI Vision resource that they were trained under, and the customer is able to make calls to those models using the Analyze Image API. When they make these calls, the custom model is loaded in memory, and the prediction infrastructure is initialized. While this happens, customers might experience longer than expected latency to receive prediction results.
Data privacy and security
As with all of the Azure AI services, developers using Image Analysis model customization should be aware of Microsoft's policies on customer data. See the Azure AI services page on the Microsoft Trust Center to learn more.
Next steps
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for