PostgreSQL extensions in Azure Database for PostgreSQL - Flexible Server
APPLIES TO:  Azure Database for PostgreSQL - Flexible Server
Azure Database for PostgreSQL - Flexible Server
Azure Database for PostgreSQL flexible server provides the ability to extend the functionality of your database using extensions. Extensions bundle multiple related SQL objects in a single package that can be loaded or removed from your database with a command. After being loaded into the database, extensions function like built-in features.
How to use PostgreSQL extensions
Before installing extensions in Azure Database for PostgreSQL flexible server, you need to allowlist these extensions for use.
Using the Azure portal:
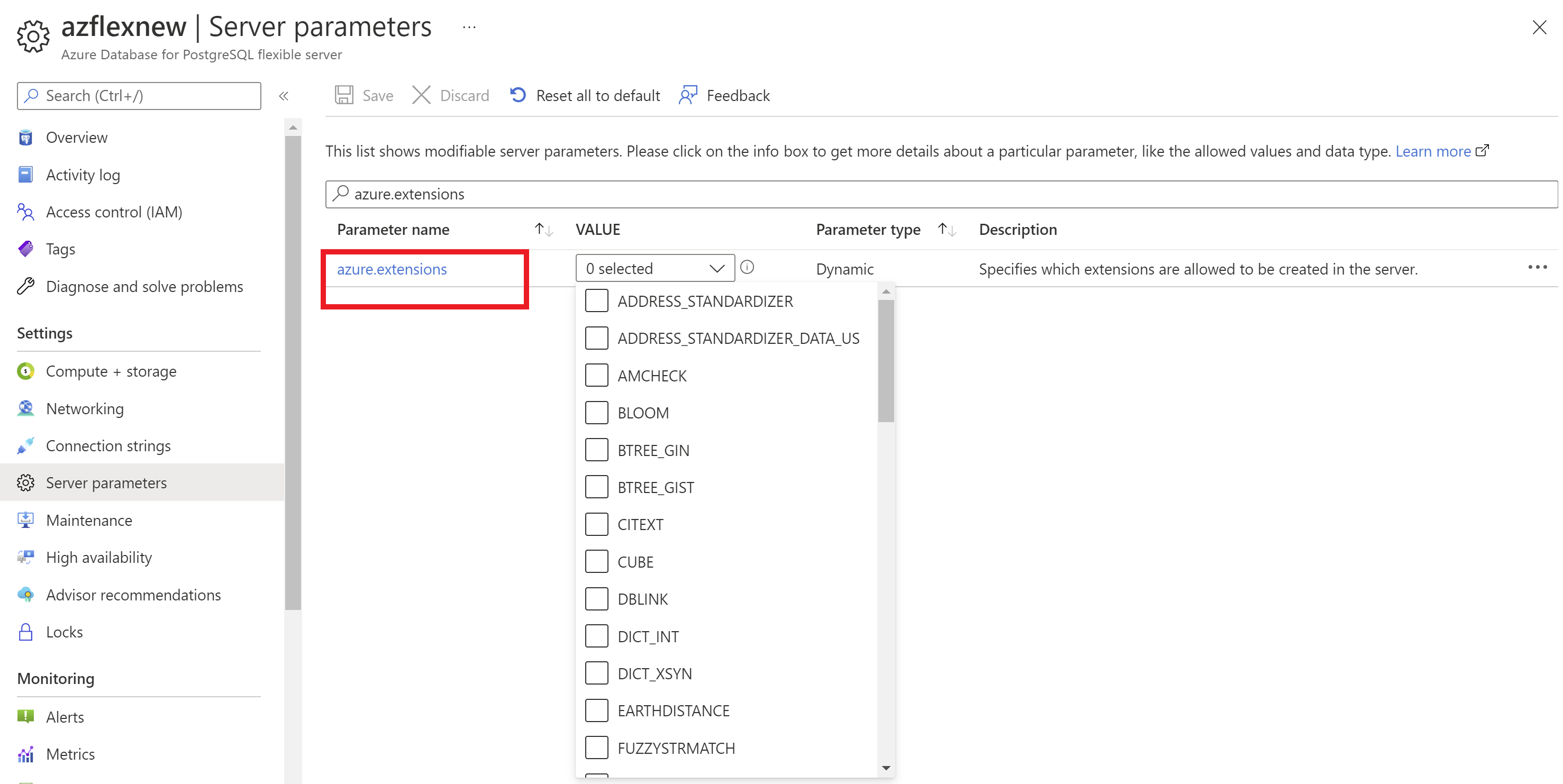
- Select your Azure Database for PostgreSQL flexible server instance.
- On the sidebar, select Server Parameters.
- Search for the
azure.extensionsparameter. - Select extensions you wish to allowlist.

Using Azure CLI:
You can allowlist extensions via CLI parameter set command.
az postgres flexible-server parameter set --resource-group <your resource group> --server-name <your server name> --subscription <your subscription id> --name azure.extensions --value <extension name>,<extension name>
Using ARM Template: Example shown below allowlists extensions dblink, dict_xsyn, pg_buffercache on the server mypostgreserver
{
"$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#",
"contentVersion": "1.0.0.0",
"parameters": {
"flexibleServers_name": {
"defaultValue": "mypostgreserver",
"type": "String"
},
"azure_extensions_set_value": {
"defaultValue": " dblink,dict_xsyn,pg_buffercache",
"type": "String"
}
},
"variables": {},
"resources": [
{
"type": "Microsoft.DBforPostgreSQL/flexibleServers/configurations",
"apiVersion": "2021-06-01",
"name": "[concat(parameters('flexibleServers_name'), '/azure.extensions')]",
"properties": {
"value": "[parameters('azure_extensions_set_value')]",
"source": "user-override"
}
}
]
}
shared_preload_libraries is a server configuration parameter determining which libraries are to be loaded when Azure Database for PostgreSQL flexible server starts. Any libraries, which use shared memory must be loaded via this parameter. If your extension needs to be added to shared preload libraries this action can be done:
Using the Azure portal:
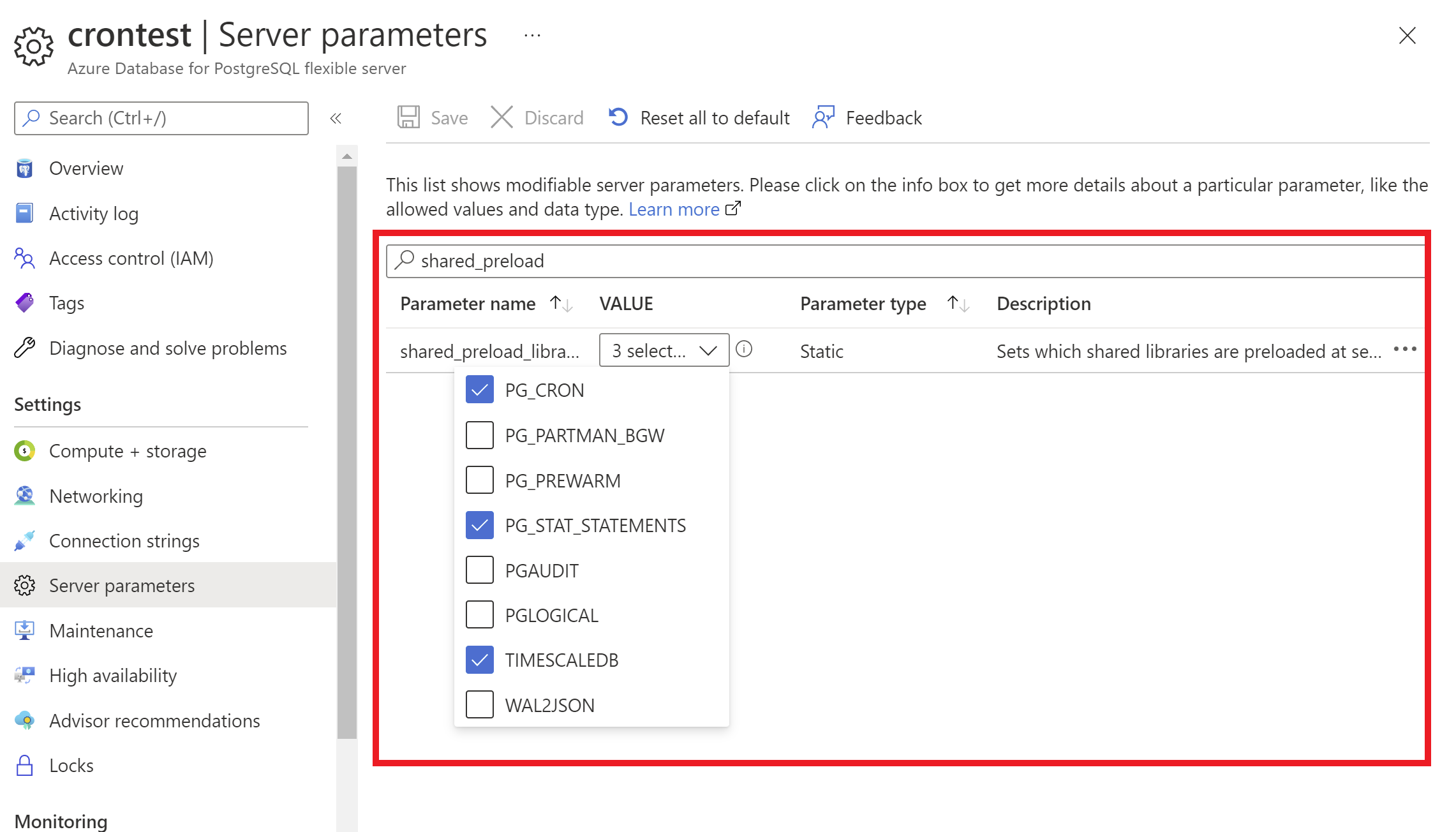
- Select your Azure Database for PostgreSQL flexible server instance.
- On the sidebar, select Server Parameters.
- Search for the
shared_preload_librariesparameter. - Select extensions you wish to add.

Using Azure CLI:
You can set shared_preload_libraries via CLI parameter set command.
az postgres flexible-server parameter set --resource-group <your resource group> --server-name <your server name> --subscription <your subscription id> --name shared_preload_libraries --value <extension name>,<extension name>
After extensions are allow-listed and loaded, these must be installed in your database before you can use them. To install a particular extension, you should run the CREATE EXTENSION command. This command loads the packaged objects into your database.
Note
Third party extensions offered in Azure Database for PostgreSQL flexible server are open source licensed code. Currently, we don't offer any third party extensions or extension versions with premium or proprietary licensing models.
Azure Database for PostgreSQL flexible server instance supports a subset of key PostgreSQL extensions as listed below. This information is also available by running SHOW azure.extensions;. Extensions not listed in this document aren't supported on Azure Database for PostgreSQL flexible server. You can't create or load your own extension in Azure Database for PostgreSQL flexible server.
Extension versions
The following extensions are available in Azure Database for PostgreSQL flexible server:
Note
Extensions in the following table with the ✔️ mark, require their corresponding libraries to be enabled in the shared_preload_libraries server parameter.
| Extension name | Description | PostgreSQL 16 | PostgreSQL 15 | PostgreSQL 14 | PostgreSQL 13 | PostgreSQL 12 | PostgreSQL 11 |
|---|---|---|---|---|---|---|---|
| address_standardizer | Used to parse an address into constituent elements. Generally used to support geocoding address normalization step. | 3.3.3 | 3.3.1 | 3.2.3 | 3.2.3 | 3.2.3 | 3.2.3 |
| address_standardizer_data_us | Address Standardizer US dataset example | 3.3.3 | 3.3.1 | 3.2.3 | 3.2.3 | 3.2.3 | 3.2.3 |
| amcheck | Functions for verifying relation integrity | 1.3 | 1.3 | 1.3 | 1.2 | 1.2 | 1.1 |
| azure_ai | Azure AI and ML Services integration for PostgreSQL | 1.1.0 | 1.1.0 | 1.1.0 | 1.1.0 | 1.1.0 | N/A |
| azure_local_ai (Preview) | Local AI capabilities for PostgreSQL | 0.1.0 | 0.1.0 | 0.1.0 | 0.1.0 | N/A | N/A |
| azure_storage | Azure integration for PostgreSQL | 1.4 ✔️ | 1.4 ✔️ | 1.4 ✔️ | 1.4 ✔️ | 1.4 ✔️ | N/A |
| bloom | Bloom access method - signature file based index | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| btree_gin | Support for indexing common datatypes in GIN | 1.3 | 1.3 | 1.3 | 1.3 | 1.3 | 1.3 |
| btree_gist | Support for indexing common datatypes in GiST | 1.7 | 1.7 | 1.6 | 1.5 | 1.5 | 1.5 |
| citext | Data type for case-insensitive character strings | 1.6 | 1.6 | 1.6 | 1.6 | 1.6 | 1.5 |
| cube | Data type for multidimensional cubes | 1.5 | 1.5 | 1.5 | 1.4 | 1.4 | 1.4 |
| dblink | Connect to other PostgreSQL databases from within a database | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 |
| dict_int | Text search dictionary template for integers | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| dict_xsyn | Text search dictionary template for extended synonym processing | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| earthdistance | Calculate great-circle distances on the surface of the Earth | 1.1 | 1.1 | 1.1 | 1.1 | 1.1 | 1.1 |
| fuzzystrmatch | Determine similarities and distance between strings | 1.2 | 1.1 | 1.1 | 1.1 | 1.1 | 1.1 |
| hstore | Data type for storing sets of (key, value) pairs | 1.8 | 1.8 | 1.8 | 1.7 | 1.6 | 1.5 |
| hypopg | Hypothetical indexes for PostgreSQL | 1.4.0 | 1.4.0 | 1.4.0 | 1.4.0 | 1.4.0 | 1.4.0 |
| intagg | Integer aggregator and enumerator (obsolete) | 1.1 | 1.1 | 1.1 | 1.1 | 1.1 | 1.1 |
| intarray | Functions, operators, and index support for 1-D arrays of integers | 1.5 | 1.5 | 1.5 | 1.3 | 1.2 | 1.2 |
| isn | Data types for international product numbering standards | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 |
| lo | Large Object maintenance | 1.1 | 1.1 | 1.1 | 1.1 | 1.1 | 1.1 |
| login_hook | Login_hook - hook to execute login_hook.login() at login time | 1.5 | 1.4 | 1.4 | 1.4 | 1.4 | 1.4 |
| ltree | Data type for hierarchical tree-like structures | 1.2 | 1.2 | 1.2 | 1.2 | 1.1 | 1.1 |
| orafce | Functions and operators that emulate a subset of functions and packages from the Oracle RDBMS | 4.4 | 3.24 | 3.18 | 3.18 | 3.18 | 3.7 |
| pageinspect | Inspect the contents of database pages at a low level | 1.12 | 1.11 | 1.9 | 1.8 | 1.7 | 1.7 |
| pgaudit | Provides auditing functionality | 16.0 ✔️ | 1.7 ✔️ | 1.6.2 ✔️ | 1.5 ✔️ | 1.4 ✔️ | 1.3.2 ✔️ |
| pg_buffercache | Examine the shared buffer cache | 1.4 | 1.3 | 1.3 | 1.3 | 1.3 | 1.3 |
| pg_cron | Job scheduler for PostgreSQL | 1.5 ✔️ | 1.4-1 ✔️ | 1.4-1 ✔️ | 1.4-1 ✔️ | 1.4-1 ✔️ | 1.4-1 ✔️ |
| pgcrypto | Cryptographic functions | 1.3 | 1.3 | 1.3 | 1.3 | 1.3 | 1.3 |
| pg_failover_slots (Preview) | Logical replication slot manager for failover purposes | 1.0.1 ✔️ | 1.0.1 ✔️ | 1.0.1 ✔️ | 1.0.1 ✔️ | 1.0.1 ✔️ | 1.0.1 ✔️ |
| pg_freespacemap | Examine the free space map (FSM) | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 |
| pg_hint_plan | Makes it possible to tweak PostgreSQL execution plans using so-called hints in SQL comments. | 1.6.0 ✔️ | 1.5 ✔️ | 1.4 ✔️ | 1.3.7 ✔️ | 1.3.7 ✔️ | 1.3.7 ✔️ |
| pglogical | PostgreSQL Logical Replication | 2.4.4 ✔️ | 2.4.2 ✔️ | 2.4.1 ✔️ | 2.4.1 ✔️ | 2.4.1 ✔️ | 2.4.1 ✔️ |
| pg_partman | Extension to manage partitioned tables by time or ID | 4.7.1 ✔️ | 4.7.1 ✔️ | 4.6.1 ✔️ | 4.5.0 ✔️ | 4.5.0 ✔️ | 4.5.0 ✔️ |
| pg_prewarm | Prewarm relation data | 1.2 ✔️ | 1.2 ✔️ | 1.2 ✔️ | 1.2 ✔️ | 1.2 ✔️ | 1.2 ✔️ |
| pg_repack | Reorganize tables in PostgreSQL databases with minimal locks | 1.4.7 | 1.4.7 | 1.4.7 | 1.4.7 | 1.4.7 | 1.4.7 |
| pgrouting | PgRouting Extension | N/A | 3.5.0 | 3.3.0 | 3.3.0 | 3.3.0 | 3.3.0 |
| pgrowlocks | Show row-level locking information | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 |
| pg_squeeze | A tool to remove unused space from a relation. | 1.6 ✔️ | 1.6 ✔️ | 1.5 ✔️ | 1.5 ✔️ | 1.5 ✔️ | 1.5 ✔️ |
| pg_stat_statements | Track planning and execution statistics of all SQL statements executed | 1.10 ✔️ | 1.10 ✔️ | 1.9 ✔️ | 1.8 ✔️ | 1.7 ✔️ | 1.6 ✔️ |
| pgstattuple | Show tuple-level statistics | 1.5 | 1.5 | 1.5 | 1.5 | 1.5 | 1.5 |
| pg_trgm | Text similarity measurement and index searching based on trigrams | 1.6 | 1.6 | 1.6 | 1.5 | 1.4 | 1.4 |
| pg_visibility | Examine the visibility map (VM) and page-level visibility info | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 |
| plpgsql | PL/pgSQL procedural language | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| plv8 | PL/JavaScript (v8) trusted procedural language | 3.1.7 | 3.1.7 | 3.0.0 | 3.0.0 | 3.0.0 | 3.0.0 |
| postgis | PostGIS geometry and geography spatial types and functions | 3.3.3 | 3.3.1 | 3.2.3 | 3.2.3 | 3.2.3 | 3.2.3 |
| postgis_raster | PostGIS raster types and functions | 3.3.3 | 3.3.1 | 3.2.3 | 3.2.3 | 3.2.3 | 3.2.3 |
| postgis_sfcgal | PostGIS SFCGAL functions | 3.3.3 | 3.3.1 | 3.2.3 | 3.2.3 | 3.2.3 | 3.2.3 |
| postgis_tiger_geocoder | PostGIS tiger geocoder and reverse geocoder | 3.3.3 | 3.3.1 | 3.2.3 | 3.2.3 | 3.2.3 | 3.2.3 |
| postgis_topology | PostGIS topology spatial types and functions | 3.3.3 | 3.3.1 | 3.2.3 | 3.2.3 | 3.2.3 | 3.2.3 |
| postgres_fdw | Foreign-data wrapper for remote PostgreSQL servers | 1.1 | 1.1 | 1.1 | 1.0 | 1.0 | 1.0 |
| semver | Semantic version data type | 0.32.1 | 0.32.0 | 0.32.0 | 0.32.0 | 0.32.0 | 0.32.0 |
| session_variable | Session_variable - registration and manipulation of session variables and constants | 3.3 | 3.3 | 3.3 | 3.3 | 3.3 | 3.3 |
| sslinfo | Information about SSL certificates | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 |
| tablefunc | Functions that manipulate whole tables, including crosstab | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| tds_fdw | Foreign data wrapper for querying a TDS database (Sybase or Microsoft SQL Server) | 2.0.3 | 2.0.3 | 2.0.3 | 2.0.3 | 2.0.3 | 2.0.3 |
| timescaledb | Enables scalable inserts and complex queries for time-series data | 2.13.0 ✔️ | 2.10.0 ✔️ | 2.10.0 ✔️ | 2.10.0 ✔️ | 2.10.0 ✔️ | 1.7.4 ✔️ |
| tsm_system_rows | TABLESAMPLE method which accepts number of rows as a limit | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| tsm_system_time | TABLESAMPLE method which accepts time in milliseconds as a limit | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| unaccent | Text search dictionary that removes accents | 1.1 | 1.1 | 1.1 | 1.1 | 1.1 | 1.1 |
| uuid-ossp | Generate universally unique identifiers (UUIDs) | 1.1 | 1.1 | 1.1 | 1.1 | 1.1 | 1.1 |
| vector | Vector data type and ivfflat and hnsw access methods | 0.7.0 | 0.7.0 | 0.7.0 | 0.7.0 | 0.7.0 | 0.5.1 |
Upgrading PostgreSQL extensions
In-place upgrades of database extensions are allowed through a simple command. This feature enables customers to automatically update their third-party extensions to the latest versions, maintaining current and secure systems without manual effort.
Updating Extensions
To update an installed extension to the latest available version supported by Azure, use the following SQL command:
ALTER EXTENSION <extension-name> UPDATE;
This command simplifies the management of database extensions by allowing users to manually upgrade to the latest version approved by Azure, enhancing both compatibility and security.
Limitations
While updating extensions is straightforward, there are certain limitations:
- Specific Version Selection: The command does not support updating to intermediate versions of an extension. It will always update to the latest available version.
- Downgrading: Does not support downgrading an extension to a previous version. If a downgrade is necessary, it might require support assistance and depends on the availability of previous version.
Viewing Installed Extensions
To list the extensions currently installed on your database, use the following SQL command:
SELECT * FROM pg_extension;
Available Extension Versions
To check which versions of an extension are available for your current database installation, execute:
SELECT * FROM pg_available_extensions WHERE name = 'azure_ai';
These commands provide necessary insights into the extension configurations of your database, helping maintain your systems efficiently and securely. By enabling easy updates to the latest extension versions, Azure Database for PostgreSQL continues to support the robust, secure, and efficient management of your database applications.
dblink and postgres_fdw
dblink and postgres_fdw allow you to connect from one Azure Database for PostgreSQL flexible server instance to another, or to another database in the same server. Azure Database for PostgreSQL flexible server supports both incoming and outgoing connections to any PostgreSQL server. The sending server needs to allow outbound connections to the receiving server. Similarly, the receiving server needs to allow connections from the sending server.
We recommend deploying your servers with virtual network integration if you plan to use these two extensions. By default virtual network integration allows connections between servers in the virtual network. You can also choose to use virtual network network security groups to customize access.
pg_prewarm
The pg_prewarm extension loads relational data into cache. Prewarming your caches means that your queries have better response times on their first run after a restart. The auto-prewarm functionality isn't currently available in Azure Database for PostgreSQL flexible server.
pg_cron
pg_cron is a simple, cron-based job scheduler for PostgreSQL that runs inside the database as an extension. The pg_cron extension can be used to run scheduled maintenance tasks within a PostgreSQL database. For example, you can run periodic vacuum of a table or removing old data jobs.
pg_cron can run multiple jobs in parallel, but it runs at most one instance of a job at a time. If a second run is supposed to start before the first one finishes, then the second run is queued and started as soon as the first run completes. This ensures that jobs run exactly as many times as scheduled and don't run concurrently with themselves.
Some examples:
To delete old data on Saturday at 3:30am (GMT).
SELECT cron.schedule('30 3 * * 6', $$DELETE FROM events WHERE event_time < now() - interval '1 week'$$);
To run vacuum every day at 10:00am (GMT) in default database postgres.
SELECT cron.schedule('0 10 * * *', 'VACUUM');
To unschedule all tasks from pg_cron.
SELECT cron.unschedule(jobid) FROM cron.job;
To see all jobs currently scheduled with pg_cron.
SELECT * FROM cron.job;
To run vacuum every day at 10:00 am (GMT) in database 'testcron' under azure_pg_admin role account.
SELECT cron.schedule_in_database('VACUUM','0 10 * * * ','VACUUM','testcron',null,TRUE);
Note
pg_cron extension is preloaded in shared_preload_libraries for every Azure Database for PostgreSQL flexible server instance inside postgres database to provide you with ability to schedule jobs to run in other databases within your Azure Database for PostgreSQL flexible server DB instance without compromising security. However, for security reasons, you still have to allow list pg_cron extension and install it using CREATE EXTENSION command.
Starting with pg_cron version 1.4, you can use the cron.schedule_in_database and cron.alter_job functions to schedule your job in a specific database and update an existing schedule respectively.
Some examples:
To delete old data on Saturday at 3:30am (GMT) on database DBName.
SELECT cron.schedule_in_database('JobName', '30 3 * * 6', $$DELETE FROM events WHERE event_time < now() - interval '1 week'$$,'DBName');
Note
cron_schedule_in_database function allows for user name as optional parameter. Setting the username to a non-null value requires PostgreSQL superuser privilege and is not supported in Azure Database for PostgreSQL flexible server. Preceding examples show running this function with optional user name parameter ommitted or set to null, which runs the job in context of user scheduling the job, which should have azure_pg_admin role privileges.
To update or change the database name for the existing schedule
SELECT cron.alter_job(job_id:=MyJobID,database:='NewDBName');
pg_failover_slots (preview)
The PG Failover Slots extension enhances Azure Database for PostgreSQL flexible server when operating with both logical replication and high availability enabled servers. It effectively addresses the challenge within the standard PostgreSQL engine that doesn't preserve logical replication slots after a failover. Maintaining these slots is critical to prevent replication pauses or data mismatches during primary server role changes, ensuring operational continuity and data integrity.
The extension streamlines the failover process by managing the necessary transfer, cleanup, and synchronization of replication slots, thus providing a seamless transition during server role changes. The extension is supported for PostgreSQL versions 11 to 16.
You can find more information and how to use the PG Failover Slots extension on its GitHub page.
Enable pg_failover_slots
To enable the PG Failover Slots extension for your Azure Database for PostgreSQL flexible server instance, you need to modify the server's configuration by including the extension in the server's shared preload libraries and adjusting a specific server parameter. Here's the process:
- Add
pg_failover_slotsto the server's shared preload libraries by updating theshared_preload_librariesparameter. - Change the server parameter
hot_standby_feedbacktoon.
Any changes to the shared_preload_libraries parameter require a server restart to take effect.
Follow these steps in the Azure portal:
- Sign in to the Azure portal and go to your Azure Database for PostgreSQL flexible server instance's page.
- In the menu on the left, select Server parameters.
- Find the
shared_preload_librariesparameter in the list and edit its value to includepg_failover_slots. - Search for the
hot_standby_feedbackparameter and set its value toon. - Select on Save to preserve your changes. Now, you'll have the option to Save and restart. Choose this to ensure that the changes take effect since modifying
shared_preload_librariesrequires a server restart.
By selecting Save and restart, your server will automatically reboot, applying the changes you've made. Once the server is back online, the PG Failover Slots extension is enabled and operational on your primary Azure Database for PostgreSQL flexible server instance, ready to handle logical replication slots during failovers.
pg_stat_statements
The pg_stat_statements extension gives you a view of all the queries that have run on your database. That is useful to get an understanding of what your query workload performance looks like on a production system.
The pg_stat_statements extension is preloaded in shared_preload_libraries on every Azure Database for PostgreSQL flexible server instance to provide you a means of tracking execution statistics of SQL statements.
However, for security reasons, you still have to allowlist pg_stat_statements extension and install it using CREATE EXTENSION command.
The setting pg_stat_statements.track, which controls what statements are counted by the extension, defaults to top, meaning all statements issued directly by clients are tracked. The two other tracking levels are none and all. This setting is configurable as a server parameter.
There's a tradeoff between the query execution information pg_stat_statements provides and the impact on server performance as it logs each SQL statement. If you aren't actively using the pg_stat_statements extension, we recommend that you set pg_stat_statements.track to none. Some third-party monitoring services might rely on pg_stat_statements to deliver query performance insights, so confirm whether this is the case for you or not.
TimescaleDB
TimescaleDB is a time-series database that is packaged as an extension for PostgreSQL. TimescaleDB provides time-oriented analytical functions, optimizations, and scales Postgres for time-series workloads. Learn more about TimescaleDB, a registered trademark of Timescale, Inc. Azure Database for PostgreSQL flexible server provides the TimescaleDB Apache-2 edition.
Install TimescaleDB
To install TimescaleDB, in addition, to allow listing it, as shown above, you need to include it in the server's shared preload libraries. A change to Postgres's shared_preload_libraries parameter requires a server restart to take effect. You can change parameters using the Azure portal or the Azure CLI.
Using the Azure portal:
Select your Azure Database for PostgreSQL flexible server instance.
On the sidebar, select Server Parameters.
Search for the
shared_preload_librariesparameter.Select TimescaleDB.
Select Save to preserve your changes. You get a notification once the change is saved.
After the notification, restart the server to apply these changes.
You can now enable TimescaleDB in your Azure Database for PostgreSQL flexible server database. Connect to the database and issue the following command:
CREATE EXTENSION IF NOT EXISTS timescaledb CASCADE;
Tip
If you see an error, confirm that you restarted your server after saving shared_preload_libraries.
You can now create a TimescaleDB hypertable from scratch or migrate existing time-series data in PostgreSQL.
Restore a Timescale database using pg_dump and pg_restore
To restore a Timescale database using pg_dump and pg_restore, you must run two helper procedures in the destination database: timescaledb_pre_restore() and timescaledb_post restore().
First, prepare the destination database:
--create the new database where you'll perform the restore
CREATE DATABASE tutorial;
\c tutorial --connect to the database
CREATE EXTENSION timescaledb;
SELECT timescaledb_pre_restore();
Now you can run pg_dump on the original database and then do pg_restore. After the restore, be sure to run the following command in the restored database:
SELECT timescaledb_post_restore();
For more details on restore method with Timescale enabled database, see Timescale documentation.
Restore a Timescale database using timescaledb-backup
While running SELECT timescaledb_post_restore() procedure listed above you might get permissions denied error updating timescaledb.restoring flag. This is due to limited ALTER DATABASE permission in Cloud PaaS database services. In this case you can perform alternative method using timescaledb-backup tool to back up and restore Timescale database. Timescaledb-backup is a program for making dumping and restoring a TimescaleDB database simpler, less error-prone, and more performant.
To do so, you should do following
- Install tools as detailed here
- Create a target Azure Database for PostgreSQL flexible server instance and database
- Enable Timescale extension as shown above
- Grant
azure_pg_adminrole to user that will be used by ts-restore - Run ts-restore to restore database
More details on these utilities can be found here.
Note
When using timescale-backup utilities to restore to Azure, since database user names for Azure Database for PostgreSQL single server must use the <user@db-name> format, you need to replace @ with %40 character encoding.
pg_hint_plan
pg_hint_plan makes it possible to tweak PostgreSQL execution plans using so-called "hints" in SQL comments, like:
/*+ SeqScan(a) */
pg_hint_plan reads hinting phrases in a comment of special form given with the target SQL statement. The special form is beginning by the character sequence "/*+" and ends with "*/". Hint phrases consist of hint name and following parameters enclosed by parentheses and delimited by spaces. New lines for readability can delimit each hinting phrase.
Example:
/*+
HashJoin(a b)
SeqScan(a)
*/
SELECT *
FROM pgbench_branches b
JOIN pgbench_accounts an ON b.bid = a.bid
ORDER BY a.aid;
The above example causes the planner to use the results of a seq scan on the table a to be combined with table b as a hash join.
To install pg_hint_plan, in addition, to allow listing it, as shown above, you need to include it in the server's shared preload libraries. A change to Postgres's shared_preload_libraries parameter requires a server restart to take effect. You can change parameters using the Azure portal or the Azure CLI.
Using the Azure portal:
Select your Azure Database for PostgreSQL flexible server instance.
On the sidebar, select Server Parameters.
Search for the
shared_preload_librariesparameter.Select pg_hint_plan.
Select Save to preserve your changes. You get a notification once the change is saved.
After the notification, restart the server to apply these changes.
You can now enable pg_hint_plan your Azure Database for PostgreSQL flexible server database. Connect to the database and issue the following command:
CREATE EXTENSION pg_hint_plan;
pg_buffercache
Pg_buffercache can be used to study the contents of shared_buffers. Using this extension you can tell if a particular relation is cached or not (in shared_buffers). This extension can help you troubleshooting performance issues (caching related performance issues).
This is part of contrib, and it's easy to install this extension.
CREATE EXTENSION pg_buffercache;
Extensions and Major Version Upgrade
Azure Database for PostgreSQL flexible server has introduced an in-place major version upgrade feature that performs an in-place upgrade of the Azure Database for PostgreSQL flexible server instance with just a click. In-place major version upgrade simplifies the Azure Database for PostgreSQL flexible server upgrade process, minimizing the disruption to users and applications accessing the server. In-place major version upgrade doesn't support specific extensions, and there are some limitations to upgrading certain extensions. The extensions Timescaledb, pgaudit, dblink, orafce, and postgres_fdw are unsupported for all Azure Database for PostgreSQL flexible server versions when using in-place major version update feature.
Related content
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for