High availability in Azure Database for PostgreSQL – Single Server
APPLIES TO:  Azure Database for PostgreSQL - Single Server
Azure Database for PostgreSQL - Single Server
Important
Azure Database for PostgreSQL - Single Server is on the retirement path. We strongly recommend that you upgrade to Azure Database for PostgreSQL - Flexible Server. For more information about migrating to Azure Database for PostgreSQL - Flexible Server, see What's happening to Azure Database for PostgreSQL Single Server?.
The Azure Database for PostgreSQL – Single Server service provides a guaranteed high level of availability with the financially backed service level agreement (SLA) for uptime. Azure Database for PostgreSQL provides high availability during planned events such as user-initiated scale compute operation, and also when unplanned events such as underlying hardware, software, or network failures occur. Azure Database for PostgreSQL can quickly recover from most critical circumstances, ensuring virtually no application downtime when using this service.
Azure Database for PostgreSQL is suitable for running mission-critical databases that require high uptime. Built on Azure architecture, the service has inherent high availability, redundancy, and resiliency capabilities to mitigate database downtime from planned and unplanned outages, without requiring you to configure any additional components.
Components in Azure Database for PostgreSQL – Single Server
| Component | Description |
|---|---|
| PostgreSQL Database Server | Azure Database for PostgreSQL provides security, isolation, resource safeguards, and fast restart capability for database servers. These capabilities facilitate operations such as scaling and database server recovery operation after an outage to happen in seconds. Data modifications in the database server typically occur in the context of a database transaction. All database changes are recorded synchronously in the form of write-ahead logs (WAL) on Azure Storage – which is attached to the database server. During the database checkpoint process, data pages from the database server memory are also flushed to the storage. |
| Remote Storage | All PostgreSQL physical data files and WAL files are stored on Azure Storage, which is architected to store three copies of data within a region to ensure data redundancy, availability, and reliability. The storage layer is also independent of the database server. It can be detached from a failed database server and reattached to a new database server within few seconds. Also, Azure Storage continuously monitors for any storage faults. If a block corruption is detected, it is automatically fixed by instantiating a new storage copy. |
| Gateway | The Gateway acts as a database proxy, routes all client connections to the database server. |
Planned downtime mitigation
Azure Database for PostgreSQL is architected to provide high availability during planned downtime operations.
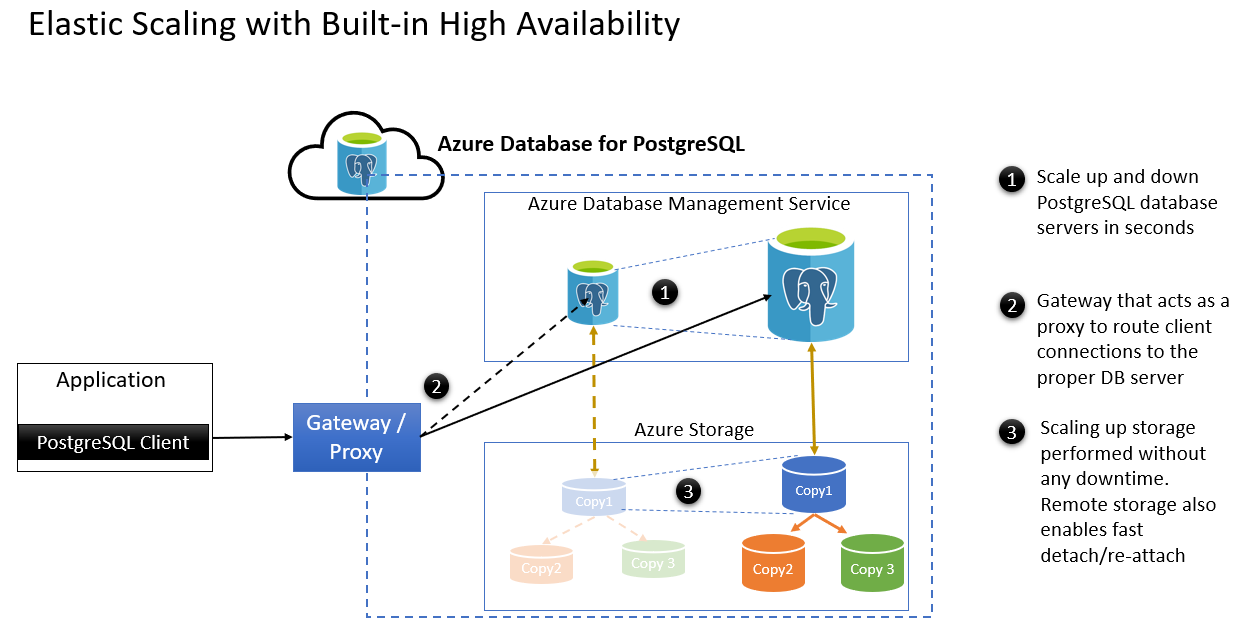
- Scale up and down PostgreSQL database servers in seconds.
- Gateway that acts as a proxy to route client connects to the proper database server.
- Scaling up of storage can be performed without any downtime. Remote storage enables fast detach/re-attach after the failover. Here are some planned maintenance scenarios:
| Scenario | Description |
|---|---|
| Compute scale up/down | When the user performs compute scale up/down operation, a new database server is provisioned using the scaled compute configuration. In the old database server, active checkpoints are allowed to complete, client connections are drained, any uncommitted transactions are canceled, and then it's shut down. The storage is then detached from the old database server and attached to the new database server. When the client application retries the connection, or tries to make a new connection, the Gateway directs the connection request to the new database server. |
| Scaling up storage | Scaling up the storage is an online operation and does not interrupt the database server. |
| New software deployment (Azure) | New features rollout or bug fixes automatically happen as part of service’s planned maintenance. For more information, refer to the documentation, and also check your portal. |
| Minor version upgrades | Azure Database for PostgreSQL automatically patches database servers to the minor version determined by Azure. It happens as part of service's planned maintenance. This would incur a short downtime in terms of seconds, and the database server is automatically restarted with the new minor version. For more information, refer to the documentation, and also check your portal. |
Unplanned downtime mitigation
Unplanned downtime can occur as a result of unforeseen failures, including underlying hardware fault, networking issues, and software bugs. If the database server goes down unexpectedly, a new database server is automatically provisioned in seconds. The remote storage is automatically attached to the new database server. PostgreSQL engine performs the recovery operation using WAL and database files, and opens up the database server to allow clients to connect. Uncommitted transactions are lost, and they have to be retried by the application. While an unplanned downtime cannot be avoided, Azure Database for PostgreSQL mitigates the downtime by automatically performing recovery operations at both database server and storage layers without requiring human intervention.
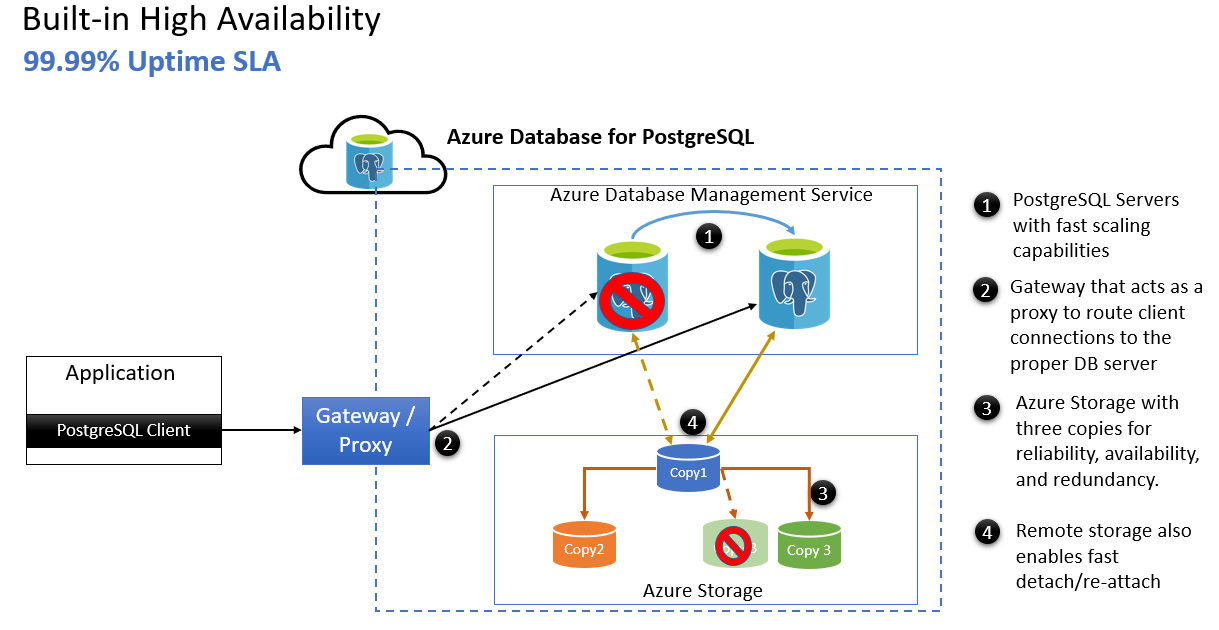
- Azure PostgreSQL servers with fast-scaling capabilities.
- Gateway that acts as a proxy to route client connections to the proper database server.
- Azure storage with three copies for reliability, availability, and redundancy.
- Remote storage also enables fast detach/re-attach after the server failover.
Unplanned downtime: Failure scenarios and service recovery
Here are some failure scenarios and how Azure Database for PostgreSQL automatically recovers:
| Scenario | Automatic recovery |
|---|---|
| Database server failure | If the database server is down because of some underlying hardware fault, active connections are dropped, and any inflight transactions are aborted. A new database server is automatically deployed, and the remote data storage is attached to the new database server. After the database recovery is complete, clients can connect to the new database server through the Gateway. The recovery time (RTO) is dependent on various factors including the activity at the time of fault such as large transaction and the amount of recovery to be performed during the database server startup process. Applications using the PostgreSQL databases need to be built in a way that they detect and retry dropped connections and failed transactions. When the application retries, the Gateway transparently redirects the connection to the newly created database server. |
| Storage failure | Applications do not see any impact for any storage-related issues such as a disk failure or a physical block corruption. As the data is stored in three copies, the copy of the data is served by the surviving storage. Block corruptions are automatically corrected. If a copy of data is lost, a new copy of the data is automatically created. |
| Compute failure | Compute failures are rare events. In the event of compute failure a new compute container is provisioned and the storage with data files is mapped to it, PostgreSQL database engine is then brought online on the new container and gateway service ensures transparent failover without any need of application changes. Please also note that compute layer has built in Availability Zone resiliency and a new compute is spun up in different Availability zone in the event of AZ compute failure. |
Here are some failure scenarios that require user action to recover:
| Scenario | Recovery plan |
|---|---|
| Region failure | Failure of a region is a rare event. However, if you need protection from a region failure, you can configure one or more read replicas in other regions for disaster recovery (DR). (See this article about creating and managing read replicas for details). In the event of a region-level failure, you can manually promote the read replica configured on the other region to be your production database server. |
| Availability zone failure | Failure of an Availability zone is also a rare event. However, if you need protection from an Availability zone failure, you can configure one or more read replicas or consider using our Flexible Server offering which provides zone-redundant high availability. |
| Logical/user errors | Recovery from user errors, such as accidentally dropped tables or incorrectly updated data, involves performing a point-in-time recovery (PITR), by restoring and recovering the data until the time just before the error had occurred. If you want to restore only a subset of databases or specific tables rather than all databases in the database server, you can restore the database server in a new instance, export the table(s) via pg_dump, and then use pg_restore to restore those tables into your database. |
Summary
Azure Database for PostgreSQL provides fast restart capability of database servers, redundant storage, and efficient routing from the Gateway. For additional data protection, you can configure backups to be geo-replicated, and also deploy one or more read replicas in other regions. With inherent high availability capabilities, Azure Database for PostgreSQL protects your databases from most common outages, and offers an industry leading, finance-backed 99.99% of uptime SLA. All these availability and reliability capabilities enable Azure to be the ideal platform to run your mission-critical applications.
Next steps
- Learn about Azure regions
- Learn about handling transient connectivity errors
- Learn how to replicate your data with read replicas
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for