Connect to Common Data Model tables in Azure Data Lake Storage
Note
Azure Active Directory is now Microsoft Entra ID. Learn more
Ingest data into Dynamics 365 Customer Insights - Data using your Azure Data Lake Storage account with Common Data Model tables. Data ingestion can be full or incremental.
Prerequisites
The Azure Data Lake Storage account must have hierarchical namespace enabled. The data must be stored in a hierarchical folder format that defines the root folder and has subfolders for each table. The subfolders can have full data or incremental data folders.
To authenticate with a Microsoft Entra service principal, make sure it's configured in your tenant. For more information, see Connect to an Azure Data Lake Storage account with a Microsoft Entra service principal.
The Azure Data Lake Storage you want to connect and ingest data from has to be in the same Azure region as the Dynamics 365 Customer Insights environment and the subscriptions must be in the same tenant. Connections to a Common Data Model folder from a data lake in a different Azure region is not supported. To know the Azure region of the environment, go to Settings > System > About in Customer Insights - Data.
Data stored in online services may be stored in a different location than where data is processed or stored. By importing or connecting to data stored in online services, you agree that data can be transferred. Learn more at the Microsoft Trust Center.
The Customer Insights - Data service principal must be in one of the following roles to access the storage account. For more information, see Grant permissions to the service principal to access the storage account.
- Storage Blob Data Reader
- Storage Blob Data Owner
- Storage Blob Data Contributor
When connecting to your Azure storage using the Azure subscription option, the user that sets up the data source connection needs at least the Storage Blob Data Contributor permissions on the storage account.
When connecting to your Azure storage using the Azure resource option, the user that sets up the data source connection needs at least the permission for the Microsoft.Storage/storageAccounts/read action on the storage account. An Azure built-in role that includes this action is the Reader role. To limit access to just the necessary action, create an Azure custom role that includes only this action.
For optimal performance, the size of a partition should be 1 GB or less and the number of partition files in a folder must not exceed 1000.
Data in your Data Lake Storage should follow the Common Data Model standard for storage of your data and have the Common Data Model manifest to represent the schema of the data files (*.csv or *.parquet). The manifest must provide the details of the tables such as table columns and data types, and the data file location and file type. For more information, see The Common Data Model manifest. If the manifest is not present, Admin users with Storage Blob Data Owner or Storage Blob Data Contributor access can define the schema when ingesting the data.
Note
If any of the fields in the .parquet files have data type Int96, the data may not display on the Tables page. We recommend using standard data types, such as the Unix timestamp format (which represents time as the number of seconds since January 1, 1970, at midnight UTC).
Limitations
- Customer Insights - Data doesn't support columns of decimal type with precision greater than 16.
Connect to Azure Data Lake Storage
Go to Data > Data sources.
Select Add a data source.
Select Azure Data Lake Common Data Model tables.

Enter a Data source name and an optional Description. The name is referenced in downstream processes and it's not possible to change it after creating the data source.
Choose one of the following options for Connect your storage using. For more information, see Connect to an Azure Data Lake Storage account with a Microsoft Entra service principal.
- Azure resource: Enter the Resource Id. (private-link.md).
- Azure subscription: Select the Subscription and then the Resource group and Storage account.
Note
You need one of the following roles to the container to create the data source:
- Storage Blob Data Reader is sufficient to read from a storage account and ingest the data to Customer Insights - Data.
- Storage Blob Data Contributor or Owner is required if you want to edit the manifest files directly in Customer Insights - Data.
Having the role on the storage account will provide the same role on all of its containers.
Optionally, if you want to ingest data from a storage account through an Azure Private Link, select Enable Private Link. For more information, see Private Links.
Choose the name of the Container that contains the data and schema (model.json or manifest.json file) to import data from, and select Next.
Note
Any model.json or manifest.json file associated with another data source in the environment won't show in the list. However, the same model.json or manifest.json file can be used for data sources in multiple environments.
To create a new schema, go to Create a new schema file.
To use an existing schema, navigate to the folder containing the model.json or manifest.cdm.json file. You can search within a directory to find the file.
Select the json file and select Next. A list of available tables displays.
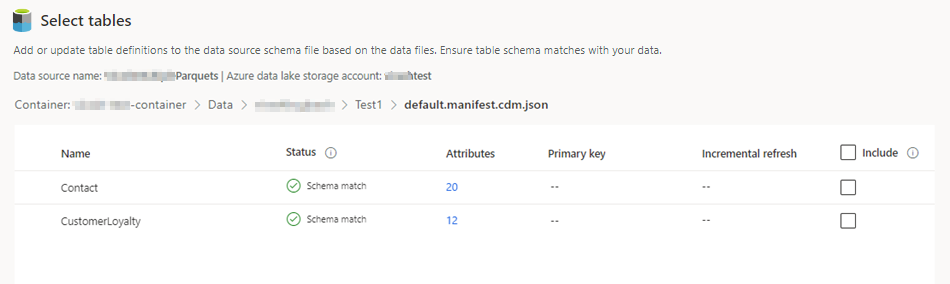
Select the tables you want to include.
Tip
To edit a table in a JSON editing interface, select the table and then Edit schema file. Make changes and select Save.
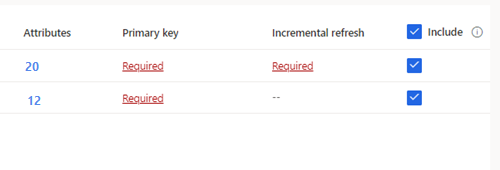
For selected tables that require incremental ingestion, Required displays under Incremental refresh. For each of these tables, see Configure an incremental refresh for Azure Data Lake data sources.
For selected tables where a primary key has not been defined, Required displays under Primary key. For each of these tables:
- Select Required. The Edit table panel displays.
- Choose the Primary key. The primary key is an attribute unique to the table. For an attribute to be a valid primary key, it shouldn't include duplicate values, missing values, or null values. String, integer, and GUID data type attributes are supported as primary keys.
- Optionally, change the partition pattern.
- Select Close to save and close the panel.
Select the number of Columns for each included table. The Manage attributes page displays.
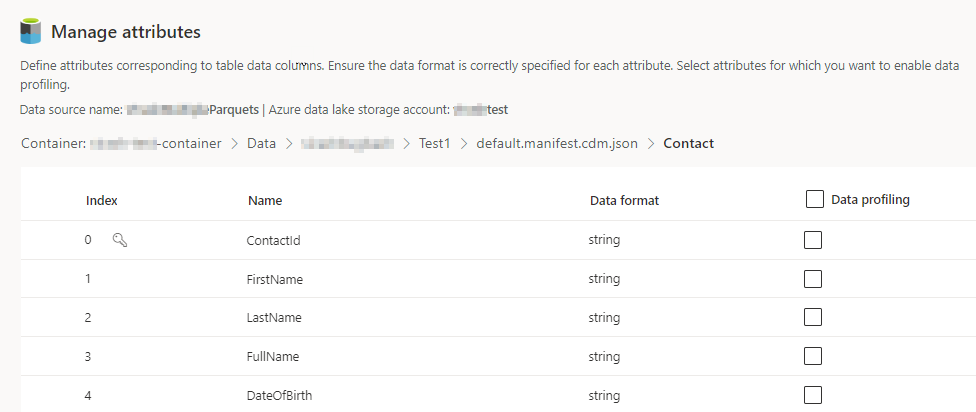
- Create new columns, edit, or delete existing columns. You can change the name, the data format, or add a semantic type.
- To enable analytics and other capabilities, select Data profiling for the whole table or for specific columns. By default, no table is enabled for data profiling.
- Select Done.
Select Save. The Data sources page opens showing the new data source in Refreshing status.
Tip
There are statuses for tasks and processes. Most processes depend on other upstream processes, such as data sources and data profiling refreshes.
Select the status to open the Progress details pane and view the progress of the tasks. To cancel the job, select Cancel job at the bottom of the pane.
Under each task, you can select See details for more progress information, such as processing time, the last processing date, and any applicable errors and warnings associated with the task or process. Select the View system status at the bottom of the panel to see other processes in the system.

Loading data can take time. After a successful refresh, the ingested data can be reviewed from the Tables page.
Create a new schema file
Select Create schema file.
Enter a name for the file and select Save.
Select New table. The New Table panel displays.
Enter the table name and choose the Data files location.
- Multiple .csv or .parquet files: Browse to the root folder, select the pattern type, and enter the expression.
- Single .csv or .parquet files: Browse to the .csv or .parquet file and select it.
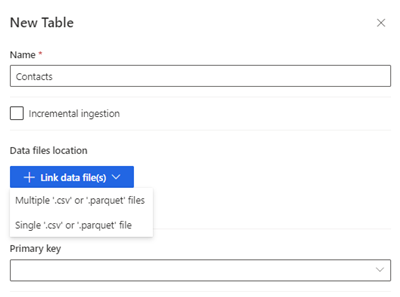
Select Save.
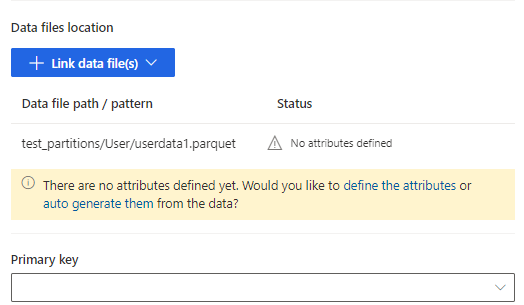
Select define the attributes to manually add the attributes, or select auto generate them. To define the attributes, enter a name, select the data format and optional semantic type. For auto-generated attributes:
After the attributes are auto-generated, select Review attributes. The Manage attributes page displays.
Ensure the data format is correct for each attribute.
To enable analytics and other capabilities, select Data profiling for the whole table or for specific columns. By default, no table is enabled for data profiling.
Select Done. The Select tables page displays.
Continue to add tables and columns, if applicable.
After all tables have been added, select Include to include the tables in the data source ingestion.
For selected tables that require incremental ingestion, Required displays under Incremental refresh. For each of these tables, see Configure an incremental refresh for Azure Data Lake data sources.
For selected tables where a primary key has not been defined, Required displays under Primary key. For each of these tables:
- Select Required. The Edit table panel displays.
- Choose the Primary key. The primary key is an attribute unique to the table. For an attribute to be a valid primary key, it shouldn't include duplicate values, missing values, or null values. String, integer, and GUID data type attributes are supported as primary keys.
- Optionally, change the partition pattern.
- Select Close to save and close the panel.
Select Save. The Data sources page opens showing the new data source in Refreshing status.
Tip
There are statuses for tasks and processes. Most processes depend on other upstream processes, such as data sources and data profiling refreshes.
Select the status to open the Progress details pane and view the progress of the tasks. To cancel the job, select Cancel job at the bottom of the pane.
Under each task, you can select See details for more progress information, such as processing time, the last processing date, and any applicable errors and warnings associated with the task or process. Select the View system status at the bottom of the panel to see other processes in the system.
Loading data can take time. After a successful refresh, the ingested data can be reviewed from the Data > Tables page.
Edit an Azure Data Lake Storage data source
You can update the Connect to storage account using option. For more information, see Connect to an Azure Data Lake Storage account with a Microsoft Entra service principal. To connect to a different container from your storage account, or change the account name, create a new data source connection.
Go to Data > Data sources. Next to the data source you'd like to update, select Edit.
Change any of the following information:
Description
Connect your storage using and connection information. You can't change Container information when updating the connection.
Note
One of the following roles must be assigned to the storage account or container:
- Storage Blob Data Reader
- Storage Blob Data Owner
- Storage Blob Data Contributor
Use managed identities for Azure with your Azure Data Lake Storage ???
Enable Private Link if you want to ingest data from a storage account through an Azure Private Link. For more information, see Private Links.
Select Next.
Change any of the following:
Navigate to a different model.json or manifest.json file with a different set of tables from the container.
To add additional tables to ingest, select New table.
To remove any already selected tables if there are no dependencies, select the table and Delete.
Important
If there are dependencies on the existing model.json or manifest.json file and the set of tables, you'll see an error message and can't select a different model.json or manifest.json file. Remove those dependencies before changing the model.json or manifest.json file or create a new data source with the model.json or manifest.json file that you want to use to avoid removing the dependencies.
To change data file location or the primary key, select Edit.
To change the incremental ingestion data, see Configure an incremental refresh for Azure Data Lake data sources.
Only change the table name to match the table name in the .json file.
Note
Always keep the table name in the same as the table name in the model.json or manifest.json file after ingestion. Customer Insights - Data validates all table names with the model.json or manifest.json during every system refresh. If a table name changes, an error occurs because Customer Insights - Data cannot find the new table name in the .json file. If an ingested table name was accidentally changed, edit the table name to match the name in the .json file.
Select Columns to add or change them, or to enable data profiling. Then select Done.
SelectSave to apply your changes and return to the Data sources page.
Tip
There are statuses for tasks and processes. Most processes depend on other upstream processes, such as data sources and data profiling refreshes.
Select the status to open the Progress details pane and view the progress of the tasks. To cancel the job, select Cancel job at the bottom of the pane.
Under each task, you can select See details for more progress information, such as processing time, the last processing date, and any applicable errors and warnings associated with the task or process. Select the View system status at the bottom of the panel to see other processes in the system.