Quickstart: Create your first pipeline to copy data
In this quickstart, you build a data pipeline to move a Sample dataset to the Lakehouse. This experience shows you a quick demo about how to use pipeline copy activity and how to load data into Lakehouse.
Prerequisites
To get started, you must complete the following prerequisites:
- A Microsoft Fabric tenant account with an active subscription. Create a free account.
- Make sure you have a Microsoft Fabric enabled Workspace: Create a workspace.
Create a data pipeline
Navigate to Power BI.
Select the Power BI icon in the bottom left of the screen, then select Data factory to open homepage of Data Factory.

Navigate to your Microsoft Fabric workspace. If you created a new workspace in the prior Prerequisites section, use this one.
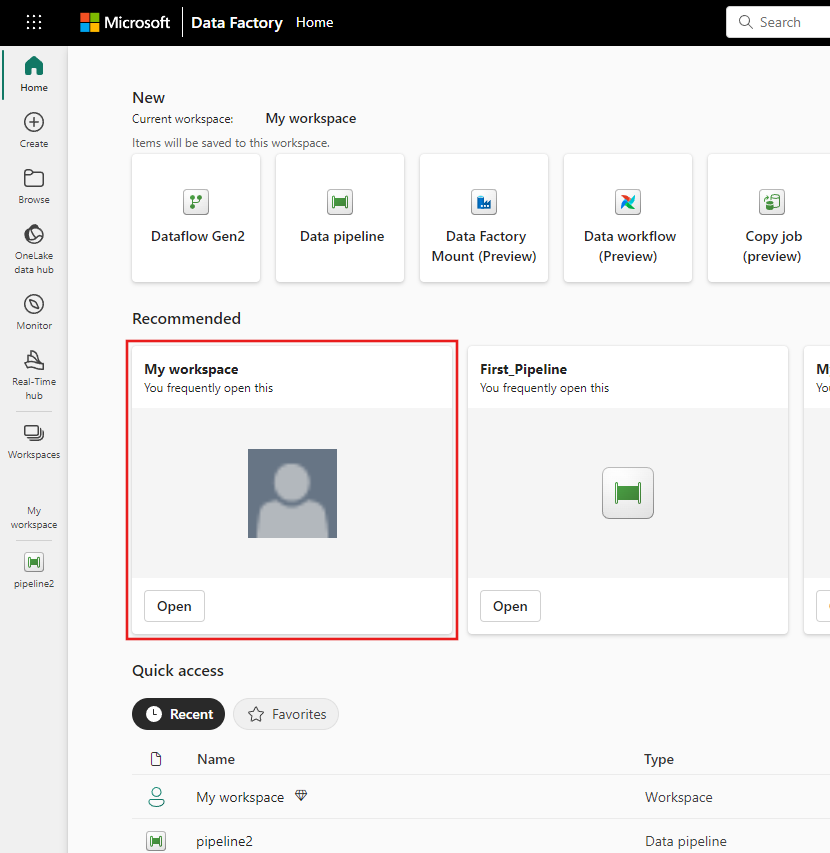
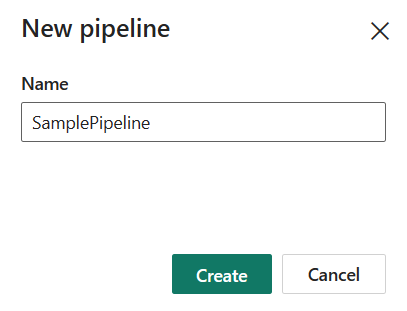
Select Data pipeline and then input a pipeline name to create a new pipeline.
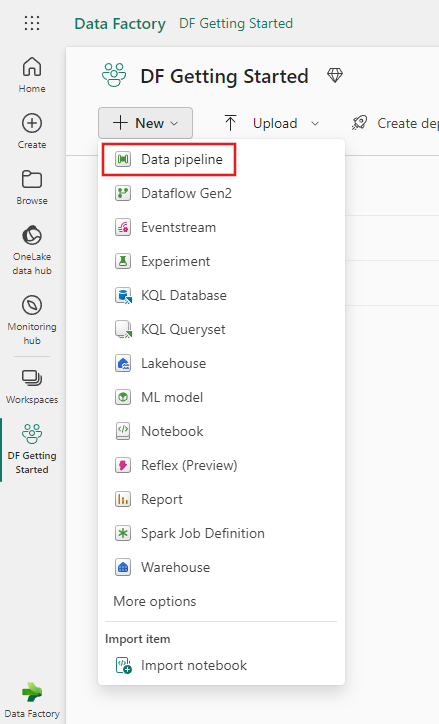
Copy data using pipeline
In this session, you start to build your first pipeline by following below steps about copying from a sample dataset provided by pipeline into Lakehouse.
Step 1: Start with the Copy data assistant
After selecting Copy data assistant on the canvas, the Copy assistant tool will be opened to get started.
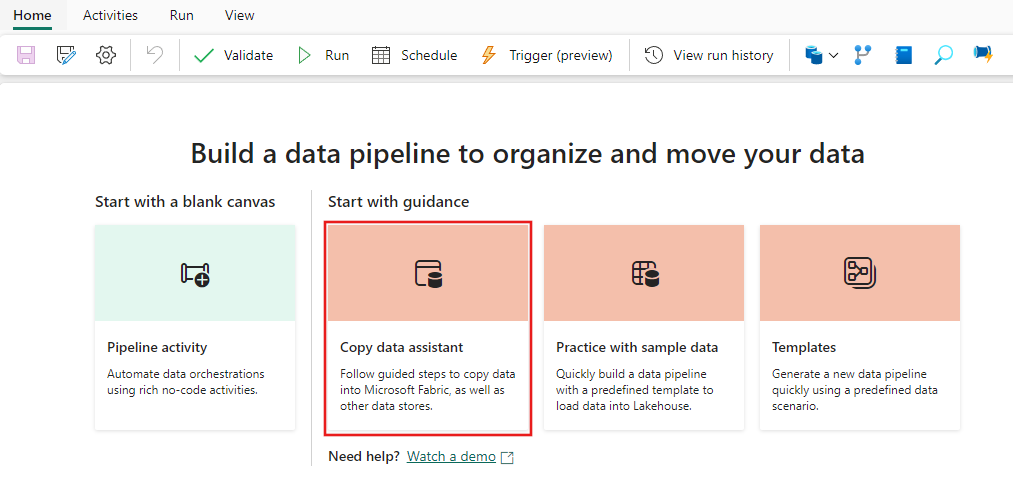
Step 2: Configure your source
Choose the Sample data tab at the top of the data source browser page, then select the Public Holidays sample data, and then Next.
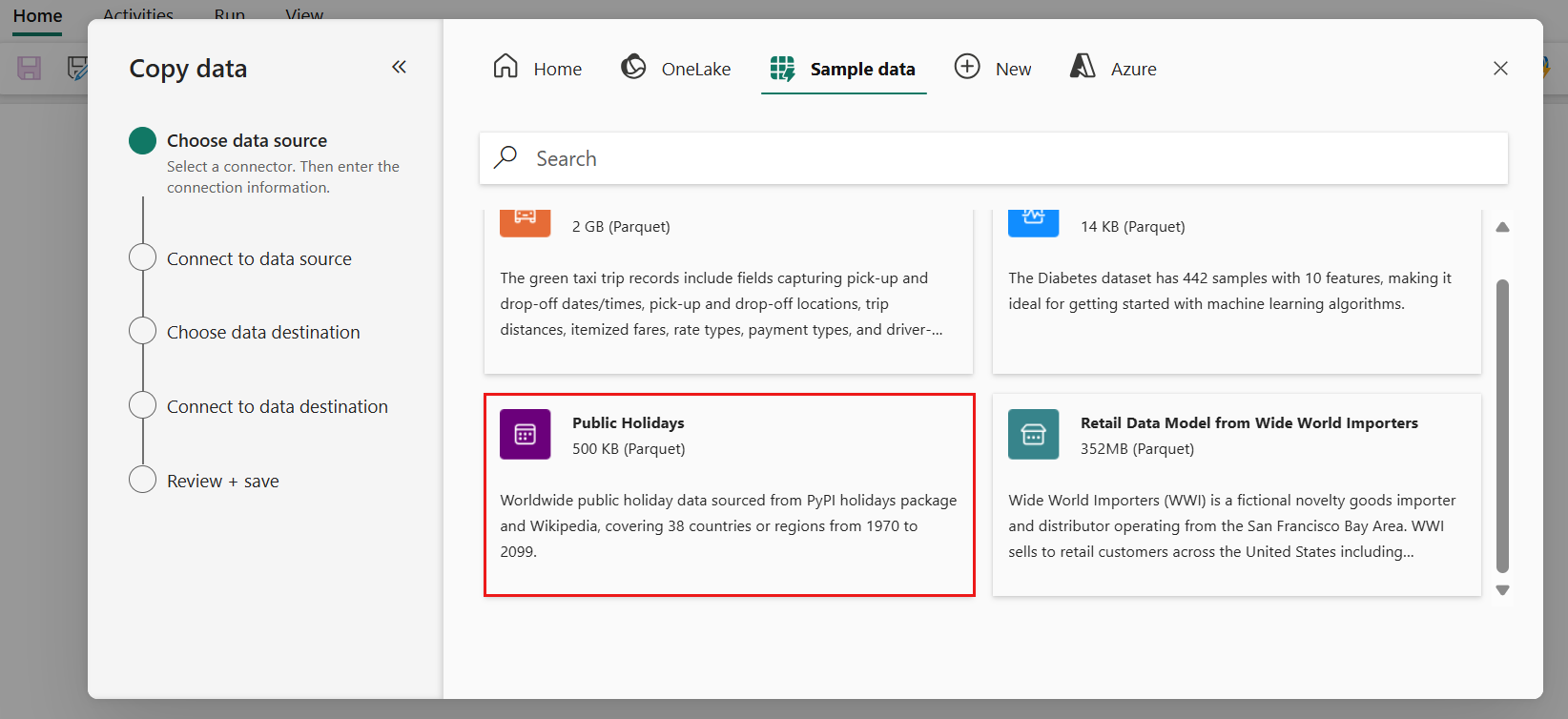
On the Connect to data source page of the assistant, the preview for the Public Holidays sample data is displayed, and then click Next.
Step 3: Configure your destination
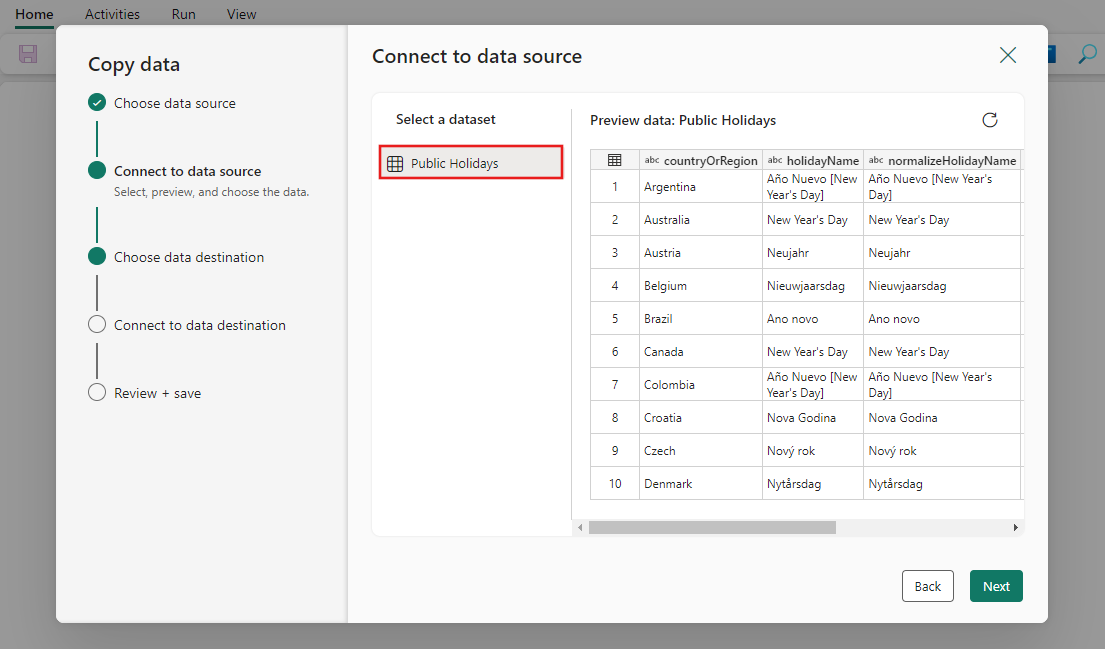
Select Lakehouse and then Next.

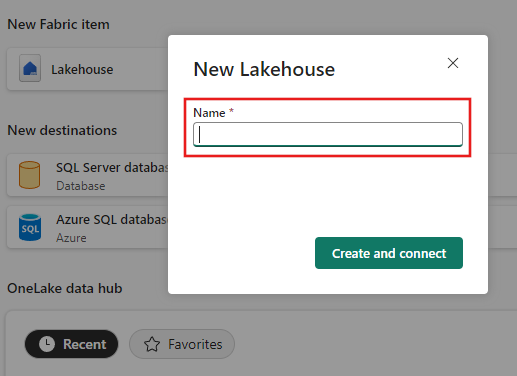
Enter a Lakehouse name, then select Create and connect.
Configure and map your source data to the destination Lakehouse table. Select Tables for the Root folder and Load to a new table for Load settings. Provide a Table name and select Next.


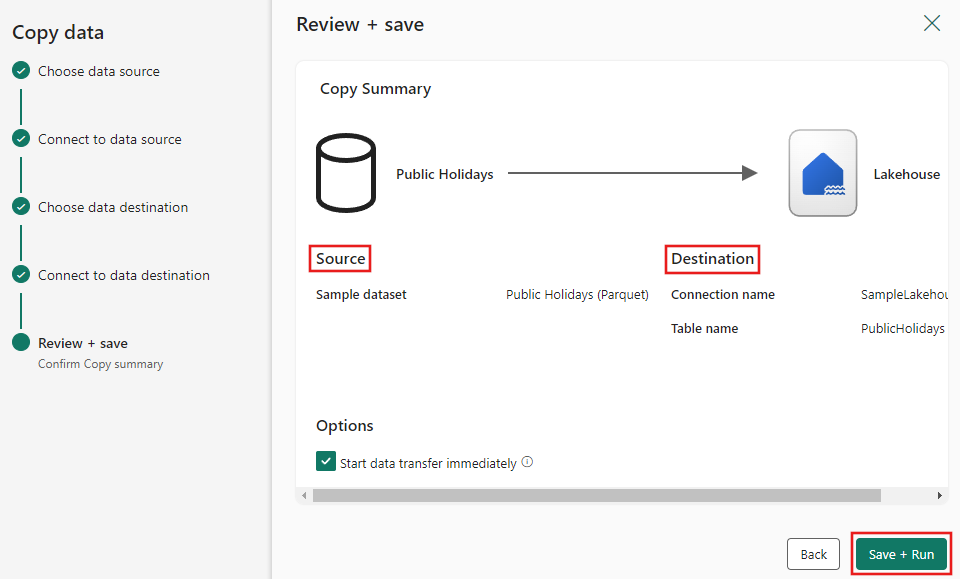
Step 4: Review and create your copy activity
Review your copy activity settings in the previous steps and select Save + run to finish. Or you can revisit the previous steps in the tool to edit your settings, if needed. If you just want to save but not run the pipeline, you can deselect the Start data transfer immediately checkbox.
The Copy activity is added to your new data pipeline canvas. All settings including advanced settings for the activity are available in the tabs below the pipeline canvas when the created Copy data activity is selected.

Run and schedule your data pipeline
If you didn't choose to Save + run on the Review + save page of the Copy data assistant, switch to the Home tab and select Run. A confirmation dialog is displayed. Then select Save and run to start the activity.

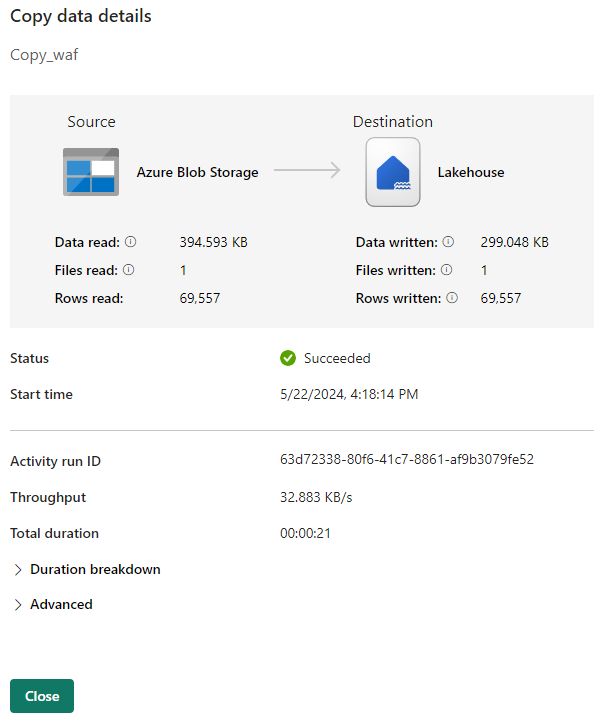
You can monitor the running process and check the results on the Output tab below the pipeline canvas. Select link for the activity name in your output to view the run details.

The run details show how much data was read and written and various other details about the run.
You can also schedule the pipeline to run with a specific frequency as required. Below is an example scheduling the pipeline to run every 15 minutes.




Related content
The pipeline in this sample shows you how to copy sample data to Lakehouse. You learned how to:
- Create a data pipeline.
- Copy data with the Copy Assistant.
- Run and schedule your data pipeline.
Next, advance to learn more about monitoring your pipeline runs.
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for