What is Azure Data Explorer?
Azure Data Explorer is a fully managed, high-performance, big data analytics platform that makes it easy to analyze high volumes of data in near real time. The Azure Data Explorer toolbox gives you an end-to-end solution for data ingestion, query, visualization, and management.
By analyzing structured, semi-structured, and unstructured data across time series, and by using Machine Learning, Azure Data Explorer makes it simple to extract key insights, spot patterns and trends, and create forecasting models. Azure Data Explorer uses a traditional relational model, organizing data into tables with strongly-typed schemas. Tables are stored within databases, and a cluster can manage multiple databases. Azure Data Explorer is scalable, secure, robust, and enterprise-ready, and is useful for log analytics, time series analytics, IoT, and general-purpose exploratory analytics.
Azure Data Explorer capabilities are extended by other services built on its query language: Kusto Query Language (KQL). These services include Azure Monitor logs, Application Insights, Time Series Insights, and Microsoft Defender for Endpoint.
When should you use Azure Data Explorer?
Use the following questions to help decide if Azure Data Explorer is right for your use case:
- Interactive analytics: Is interactive analysis part of the solution? For example, aggregation, correlation, or anomaly detection.
- Variety, Velocity, Volume: Is your schema diverse? Do you need to ingest massive amounts of data in near real-time?
- Data organization: Do you want to analyze raw data? For example, not fully curated star schema.
- Query concurrency: Will multiple users or processes use Azure Data Explorer?
- Build vs Buy: Do you plan on customizing your data platform?
Azure Data Explorer is ideal for enabling interactive analytics capabilities over high velocity, diverse raw data. Use the following decision tree to help you decide if Azure Data Explorer is right for you:
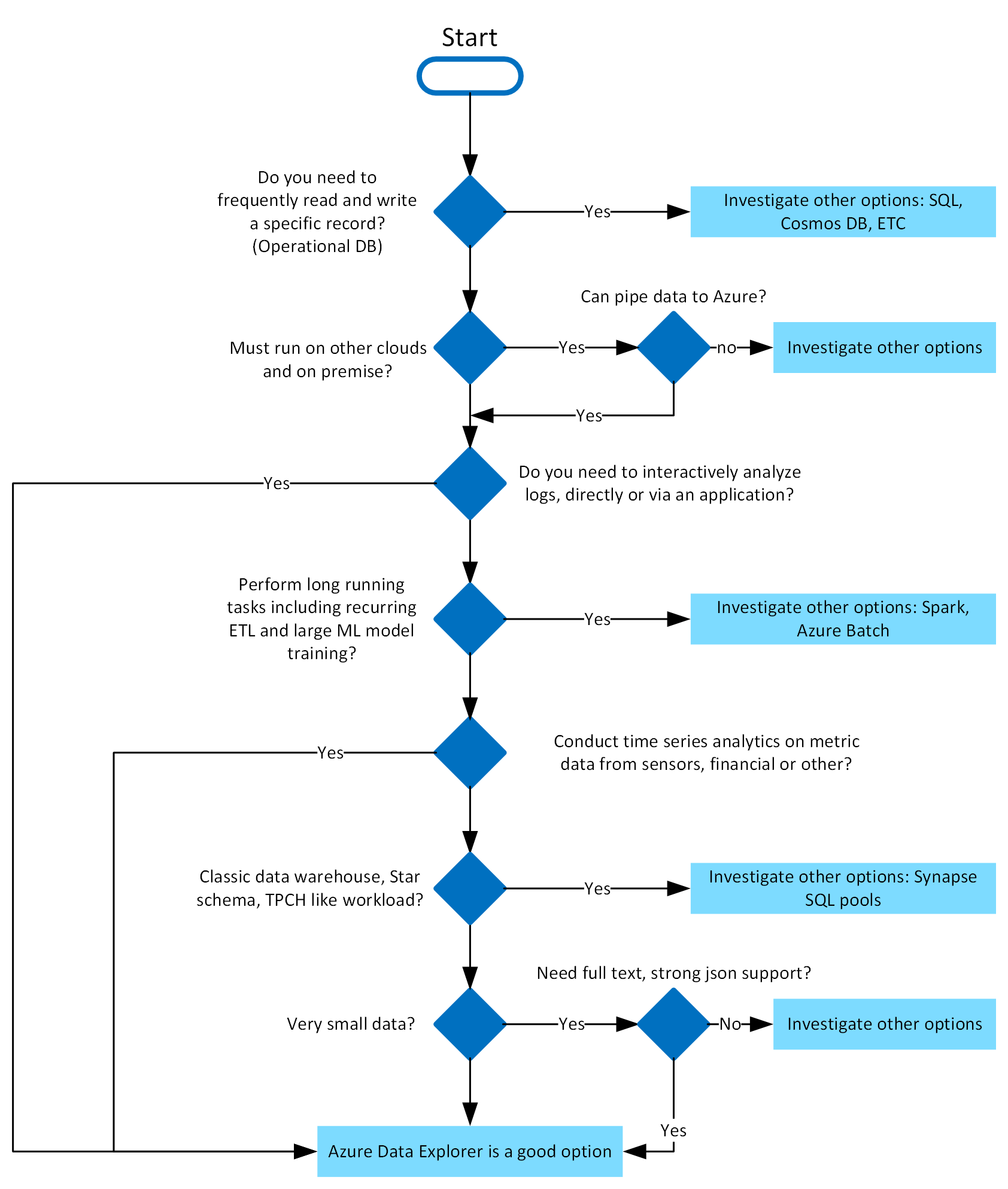
What makes Azure Data Explorer unique?
Data velocity, variety, and volume
With Azure Data Explorer, you can ingest terabytes of data in minutes via queued ingestion or streaming ingestion. You can query petabytes of data, with results returned within milliseconds to seconds. Azure Data Explorer provides high velocity (millions of events per second), low latency (seconds), and linear scale ingestion of raw data. Ingest your data in different formats and structures, flowing from various pipelines and sources.
User-friendly query language
Query Azure Data Explorer with the Kusto Query Language (KQL), an open-source language initially invented by the team. The language is simple to understand and learn, and highly productive. You can use simple operators and advanced analytics. Azure Data Explorer also supports T-SQL.
Advanced analytics
Use Azure Data Explorer for time series analysis with a large set of functions including: adding and subtracting time series, filtering, regression, seasonality detection, geospatial analysis, anomaly detection, scanning, and forecasting. Time series functions are optimized for processing thousands of time series in seconds. Pattern detection is made easy with cluster plugins that can diagnose anomalies and do root cause analysis. You can also extend Azure Data Explorer capabilities by embedding python code in KQL queries.
Easy-to-use wizard
The ingestion wizard makes the data ingestion process easy, fast, and intuitive. The Azure Data Explorer web UI provides an intuitive and guided experience that helps you ramp-up quickly to start ingesting data, creating database tables, and mapping structures. It enables one time or a continuous ingestion from various sources and in various data formats. Table mappings and schema are auto suggested and easy to modify.
Versatile data visualization
Data visualization helps you gain important insights. Azure Data Explorer offers built-in visualization and dashboarding out of the box, with support for various charts and visualizations. It has native integration with Power BI, native connectors for Grafana, Kibana and Databricks, ODBC support for Tableau, Sisense, Qlik, and more.
Automatic ingest, process, and export
Azure Data Explorer supports server-side stored functions, continuous ingest, and continuous export to Azure Data Lake store. It also supports ingestion time-mapping transformations on the server side, update policies, and precomputed scheduled aggregates with materialized views.
Azure Data Explorer flow
The following diagram shows the different aspects of working with Azure Data Explorer.
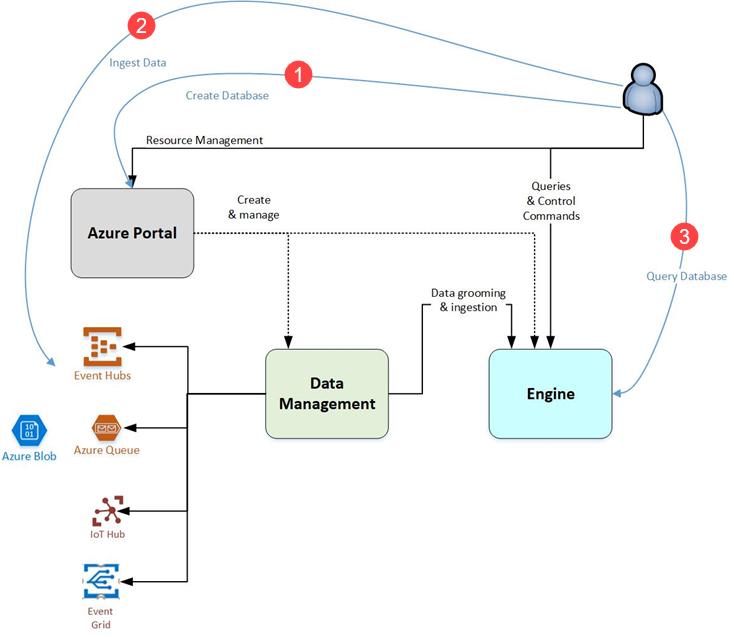
Generally speaking, when you interact with Azure Data Explorer, you're going to go through the following workflow:
Note
You can access your Azure Data Explorer resources either in the Azure Data Explorer web UI or by using SDKs.
Create database: Create a cluster and then create one or more databases in that cluster. Each Azure Data Explorer cluster can hold up to 10,000 databases and each database up to 10,000 tables. The data in each table is stored in data shards also called "extents". All data is automatically indexed and partitioned based on the ingestion time. This means you can store a lot of varied data and because of the way it's stored, you get fast access to querying it. Quickstart: Create an Azure Data Explorer cluster and database
Ingest data: Load data into database tables so that you can run queries against it. Azure Data Explorer supports several ingestion methods, each with its own target scenarios. These methods include ingestion tools, connectors and plugins to diverse services, managed pipelines, programmatic ingestion using SDKs, and direct access to ingestion. Get started with the ingestion wizard.
Query database: Azure Data Explorer uses the Kusto Query Language, which is an expressive, intuitive, and highly productive query language. It offers a smooth transition from simple one-liners to complex data processing scripts, and supports querying structured, semi-structured, and unstructured (text search) data. There's a wide variety of query language operators and functions (aggregation, filtering, time series functions, geospatial functions, joins, unions, and more) in the language. KQL supports cross-cluster and cross-database queries, and is feature rich from a parsing (json, XML, and more) perspective. The language also natively supports advanced analytics.
Use the web application to run, review, and share queries and results. You can also send queries programmatically (using an SDK) or to a REST API endpoint. If you're familiar with SQL, get started with the SQL to Kusto cheat sheet. Quickstart: Query data in Azure Data Explorer web UI
Visualize results: Use different visual displays of your data in the native Azure Data Explorer Dashboards. You can also display your results using connectors to some of the leading visualization services, such as Power BI and Grafana. Azure Data Explorer also has ODBC and JDBC connector support to tools such as Tableau and Sisense.
How to provide feedback
We would be thrilled to hear your feedback about Azure Data Explorer and the Kusto Query Language at:
- Ask questions
- Make product suggestions in User Voice
Related content
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for