Azure SQL Database elastic query overview (preview)
Applies to: ![]() Azure SQL Database
Azure SQL Database
The elastic query feature (in preview) enables you to run a Transact-SQL query that spans multiple databases in Azure SQL Database. It allows you to perform cross-database queries to access remote tables, and to connect Microsoft and third-party tools (Excel, Power BI, Tableau, etc.) to query across data tiers with multiple databases. Using this feature, you can scale out queries to large data tiers and visualize the results in business intelligence (BI) reports.
Why use elastic queries
Azure SQL Database
Query across databases in Azure SQL Database completely in T-SQL. This allows for read-only querying of remote databases and provides an option for current SQL Server customers to migrate applications using three- and four-part names or linked server to SQL Database.
Available on all service tiers
Elastic query is supported in all service tiers of Azure SQL Database. See the section on Preview Limitations below on performance limitations for lower service tiers.
Push parameters to remote databases
Elastic queries can now push SQL parameters to the remote databases for execution.
Stored procedure execution
Execute remote stored procedure calls or remote functions using sp_execute _remote.
Flexibility
External tables with elastic query can refer to remote tables with a different schema or table name.
Elastic query scenarios
The goal is to facilitate querying scenarios where multiple databases contribute rows into a single overall result. The query can either be composed by the user or application directly, or indirectly through tools that are connected to the database. This is especially useful when creating reports, using commercial BI or data integration tools, or any application that cannot be changed. With an elastic query, you can query across several databases using the familiar SQL Server connectivity experience in tools such as Excel, Power BI, Tableau, or Cognos. An elastic query allows easy access to an entire collection of databases through queries issued by SQL Server Management Studio or Visual Studio, and facilitates cross-database querying from Entity Framework or other ORM environments. Figure 1 shows a scenario where an existing cloud application (which uses the elastic database client library) builds on a scaled-out data tier, and an elastic query is used for cross-database reporting.
Figure 1 Elastic query used on scaled-out data tier
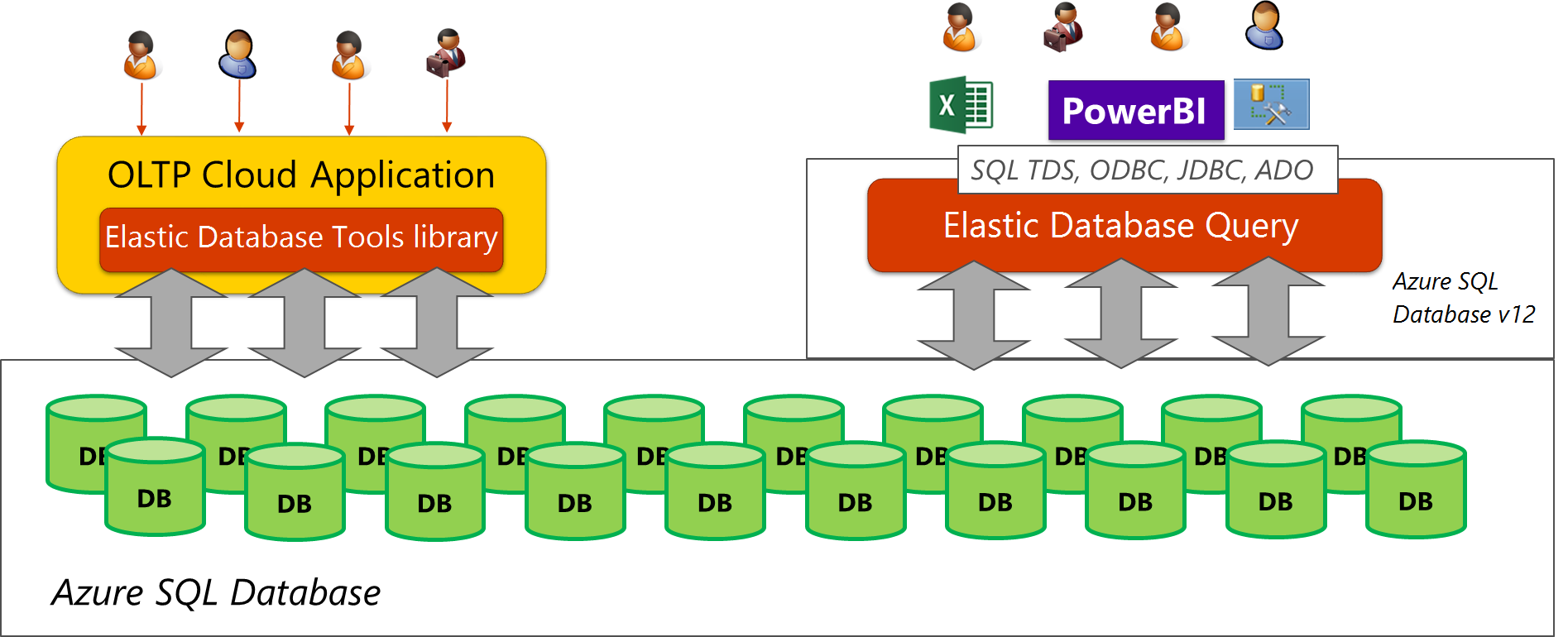
Customer scenarios for elastic query are characterized by the following topologies:
- Vertical partitioning - Cross-database queries (Topology 1): The data is partitioned vertically between a number of databases in a data tier. Typically, different sets of tables reside on different databases. That means that the schema is different on different databases. For instance, all tables for inventory are on one database while all accounting-related tables are on a second database. Common use cases with this topology require one to query across or to compile reports across tables in several databases.
- Horizontal Partitioning - Sharding (Topology 2): Data is partitioned horizontally to distribute rows across a scaled out data tier. With this approach, the schema is identical on all participating databases. This approach is also called "sharding". Sharding can be performed and managed using (1) the elastic database tools libraries or (2) self-sharding. An elastic query is used to query or compile reports across many shards. Shards are typically databases within an elastic pool. You can think of elastic query as an efficient way for querying all databases of elastic pool at once, as long as databases share the common schema.
Note
Elastic query works best for reporting scenarios where most of the processing (filtering, aggregation) can be performed on the external source side. It is not suitable for ETL operations where large amount of data is being transferred from remote database(s). For heavy reporting workloads or data warehousing scenarios with more complex queries, also consider using Azure Synapse Analytics.
Vertical partitioning - cross-database queries
To begin coding, see Getting started with cross-database query (vertical partitioning).
An elastic query can be used to make data located in a database in SQL Database available to other databases in SQL Database. This allows queries from one database to refer to tables in any other remote database in SQL Database. The first step is to define an external data source for each remote database. The external data source is defined in the local database from which you want to gain access to tables located on the remote database. No changes are necessary on the remote database. For typical vertical partitioning scenarios where different databases have different schemas, elastic queries can be used to implement common use cases such as access to reference data and cross-database querying.
Important
You must possess ALTER ANY EXTERNAL DATA SOURCE permission. This permission is included with the ALTER DATABASE permission. ALTER ANY EXTERNAL DATA SOURCE permissions are needed to refer to the underlying data source.
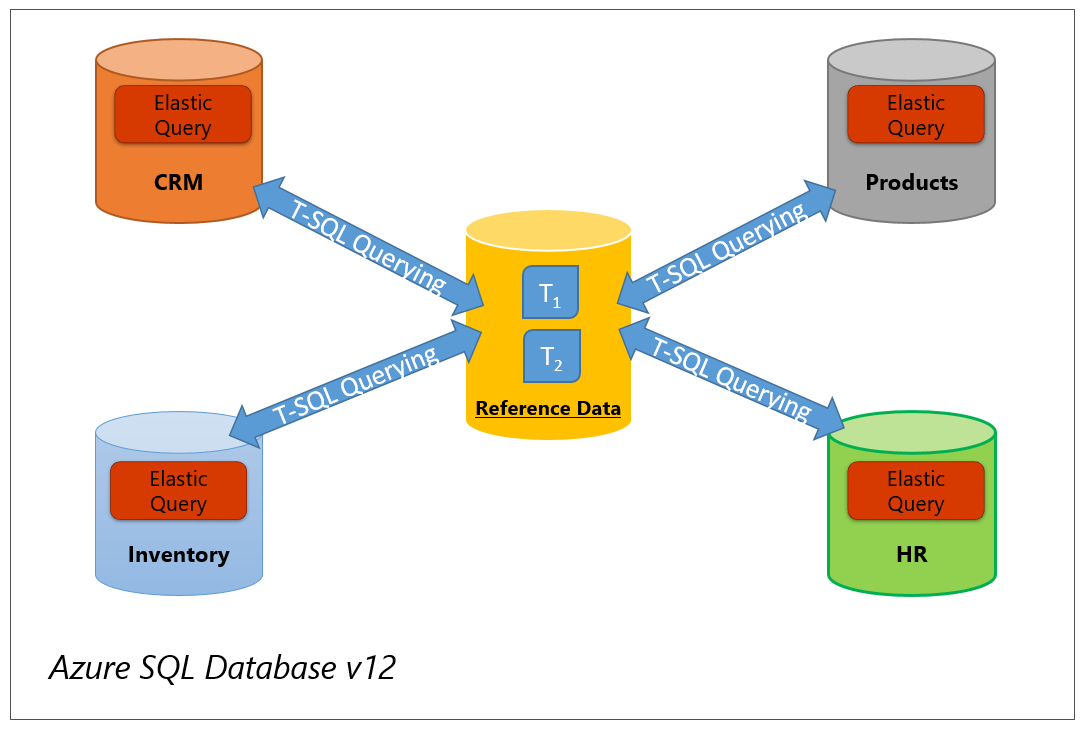
Reference data: The topology is used for reference data management. In the figure below, two tables (T1 and T2) with reference data are kept on a dedicated database. Using an elastic query, you can now access tables T1 and T2 remotely from other databases, as shown in the figure. Use topology 1 if reference tables are small or remote queries into reference table have selective predicates.
Figure 2 Vertical partitioning - Using elastic query to query reference data
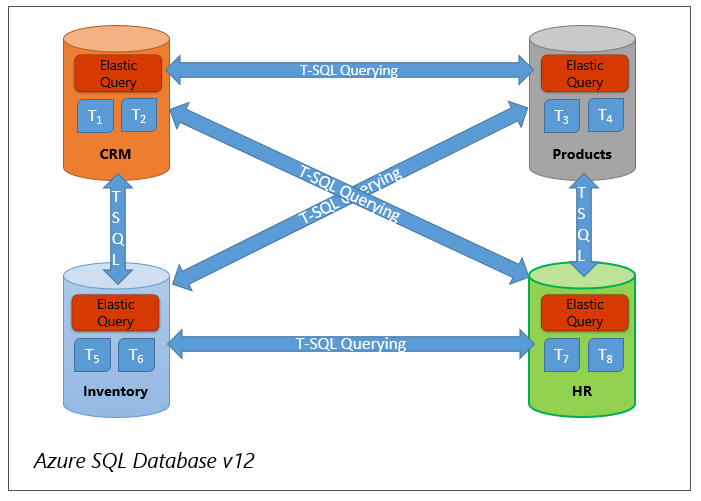
Cross-database querying: Elastic queries enable use cases that require querying across several databases in SQL Database. Figure 3 shows four different databases: CRM, Inventory, HR, and Products. Queries performed in one of the databases also need access to one or all the other databases. Using an elastic query, you can configure your database for this case by running a few simple DDL statements on each of the four databases. After this one-time configuration, access to a remote table is as simple as referring to a local table from your T-SQL queries or from your BI tools. This approach is recommended if the remote queries do not return large results.
Figure 3 Vertical partitioning - Using elastic query to query across various databases
The following steps configure elastic database queries for vertical partitioning scenarios that require access to a table located on remote databases in SQL Database with the same schema:
- CREATE MASTER KEY mymasterkey
- CREATE DATABASE SCOPED CREDENTIAL mycredential
- CREATE/DROP EXTERNAL DATA SOURCE mydatasource of type RDBMS
- CREATE/DROP EXTERNAL TABLE mytable
After running the DDL statements, you can access the remote table "mytable" as though it were a local table. Azure SQL Database automatically opens a connection to the remote database, processes your request on the remote database, and returns the results.
Horizontal partitioning - sharding
Using elastic query to perform reporting tasks over a sharded, that is, horizontally partitioned, data tier requires an elastic database shard map to represent the databases of the data tier. Typically, only a single shard map is used in this scenario and a dedicated database with elastic query capabilities (head node) serves as the entry point for reporting queries. Only this dedicated database needs access to the shard map. Figure 4 illustrates this topology and its configuration with the elastic query database and shard map. For more information about the elastic database client library and creating shard maps, see Shard map management.
Figure 4 Horizontal partitioning - Using elastic query for reporting over sharded data tiers
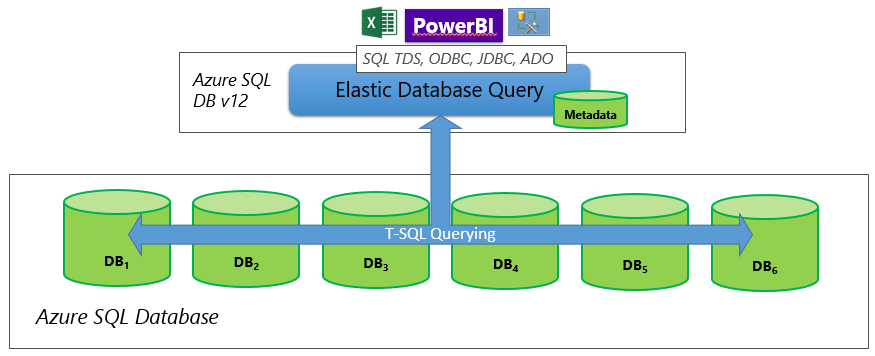
Note
Elastic Query Database (head node) can be separate database, or it can be the same database that hosts the shard map. Whatever configuration you choose, make sure that service tier and compute size of that database is high enough to handle the expected amount of login/query requests.
The following steps configure elastic database queries for horizontal partitioning scenarios that require access to a set of tables located on (typically) several remote databases in SQL Database:
- CREATE MASTER KEY mymasterkey
- CREATE DATABASE SCOPED CREDENTIAL mycredential
- Create a shard map representing your data tier using the elastic database client library.
- CREATE/DROP EXTERNAL DATA SOURCE mydatasource of type SHARD_MAP_MANAGER
- CREATE/DROP EXTERNAL TABLE mytable
Once you have performed these steps, you can access the horizontally partitioned table "mytable" as though it were a local table. Azure SQL Database automatically opens multiple parallel connections to the remote databases where the tables are physically stored, processes the requests on the remote databases, and returns the results. More information on the steps required for the horizontal partitioning scenario can be found in elastic query for horizontal partitioning.
To begin coding, see Getting started with elastic query for horizontal partitioning (sharding).
Important
Successful execution of elastic query over a large set of databases relies heavily on the availability of each of databases during the query execution. If one of databases is not available, entire query will fail. If you plan to query hundreds or thousands of databases at once, make sure your client application has retry logic embedded, or consider leveraging elastic jobs and querying smaller subsets of databases, consolidating results of each query into a single destination.
T-SQL querying
Once you have defined your external data sources and your external tables, you can use regular SQL Server connection strings to connect to the databases where you defined your external tables. You can then run T-SQL statements over your external tables on that connection with the limitations outlined below. You can find more information and examples of T-SQL queries in the documentation topics for horizontal partitioning and vertical partitioning.
Connectivity for tools
You can use regular SQL Server connection strings to connect your applications and BI or data integration tools to databases that have external tables. Make sure that SQL Server is supported as a data source for your tool. Once connected, refer to the elastic query database and the external tables in that database just like you would do with any other SQL Server database that you connect to with your tool.
Important
Elastic queries are only supported when connecting with SQL Server Authentication.
Cost
Elastic query is included in the cost of Azure SQL Database. Note that topologies where your remote databases are in a different data center than the elastic query endpoint are supported, but data egress from remote databases is charged regularly Azure rates.
Preview limitations
- Running your first elastic query can take up to a few minutes on smaller resources and Standard and General Purpose service tier. This time is necessary to load the elastic query functionality; loading performance improves with higher service tiers and compute sizes.
- Scripting of external data sources or external tables from SSMS or SSDT is not yet supported.
- Import/Export for SQL Database does not yet support external data sources and external tables. If you need to use Import/Export, drop these objects before exporting and then re-create them after importing.
- Elastic query currently only supports read-only access to external tables. You can, however, use full Transact-SQL functionality on the database where the external table is defined. This can be useful to, e.g., persist temporary results using, for example, SELECT <column_list> INTO <local_table>, or to define stored procedures on the elastic query database that refer to external tables.
- Except for nvarchar(max), LOB types (including spatial types) are not supported in external table definitions. As a workaround, you can create a view on the remote database that casts the LOB type into nvarchar(max), define your external table over the view instead of the base table and then cast it back into the original LOB type in your queries.
- Columns of nvarchar(max) data type in result set disable advanced batching techniques used in Elastic Query implementation and may affect performance of query for an order of magnitude, or even two orders of magnitude in non-canonical use cases where large amount of non-aggregated data is being transferred as a result of query.
- Column statistics over external tables are currently not supported. Table statistics are supported, but need to be created manually.
- Cursors are not supported for external tables in Azure SQL Database.
- Elastic query works with Azure SQL Database only. You cannot use it for querying a SQL Server instance.
- Private links are currently not supported with elastic query for those databases that are targets of external data sources.
Share your Feedback
Share feedback on your experience with elastic queries with us below, on the MSDN forums, or on Stack Overflow. We are interested in all kinds of feedback about the service (defects, rough edges, feature gaps).
Next steps
- For a vertical partitioning tutorial, see Getting started with cross-database query (vertical partitioning).
- For syntax and sample queries for vertically partitioned data, see Querying vertically partitioned data)
- For a horizontal partitioning (sharding) tutorial, see Getting started with elastic query for horizontal partitioning (sharding).
- For syntax and sample queries for horizontally partitioned data, see Querying horizontally partitioned data)
- See sp_execute _remote for a stored procedure that executes a Transact-SQL statement on a single remote Azure SQL Database or set of databases serving as shards in a horizontal partitioning scheme.
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for