Get started with evaluating answers in a chat app in JavaScript
This article shows you how to evaluate a chat app's answers against a set of correct or ideal answers (known as ground truth). Whenever you change your chat application in a way which affects the answers, run an evaluation to compare the changes. This demo application offers tools you can use today to make it easier to run evaluations.
By following the instructions in this article, you will:
- Use provided sample prompts tailored to the subject domain. These are already in the repository.
- Generate sample user questions and ground truth answers from your own documents.
- Run evaluations using a sample prompt with the generated user questions.
- Review analysis of answers.
Note
This article uses one or more AI app templates as the basis for the examples and guidance in the article. AI app templates provide you with well-maintained, easy to deploy reference implementations that help to ensure a high-quality starting point for your AI apps.
Architectural overview
Key components of the architecture include:
- Azure-hosted chat app: The chat app runs in Azure App Service. The chat app conforms to the chat protocol, which allows the evaluations app to run against any chat app that conforms to the protocol.
- Azure AI Search: The chat app uses Azure AI Search to store the data from your own documents.
- Sample questions generator: Can generate a number of questions for each document along with the ground truth answer. The more questions, the longer the evaluation.
- Evaluator runs sample questions and prompts against the chat app and returns the results.
- Review tool allows you to review the results of the evaluations.
- Diff tool allows you to compare the answers between evaluations.
When you deploy this evaluation to Azure, the Azure OpenAI endpoint is created for the GPT-4 model with its own capacity. When evaluating chat applications, it is important that the evaluator has its own OpenAI resource using GPT-4 with its own capacity.
Prerequisites
Azure subscription. Create one for free
Access granted to Azure OpenAI in the desired Azure subscription.
Currently, access to this service is granted only by application. You can apply for access to Azure OpenAI by completing the form at https://aka.ms/oai/access.
Deploy a chat app
These chat apps load the data into the Azure AI Search resource. This resource is required for the evaluations app to work. Don't complete the Clean up resources section of the previous procedure.
You'll need the following Azure resource information from that deployment, which is referred to as the chat app in this article:
- Chat API URI: The service backend endpoint shown at the end of the
azd upprocess. - Azure AI Search. The following values are required:
- Resource name: The name of the Azure AI Search resource name, reported as
Search serviceduring theazd upprocess. - Index name: The name of the Azure AI Search index where your documents are stored. This can be found in the Azure portal for the Search service.
- Resource name: The name of the Azure AI Search resource name, reported as
The Chat API URL allows the evaluations to make requests through your backend application. The Azure AI Search information allows the evaluation scripts to use the same deployment as your backend, loaded with the documents.
Once you have this information collected, you shouldn't need to use the chat app development environment again. It's referred to later in this article several times to indicate how the chat app is used by the Evaluations app. Don't delete the chat app resources until you complete the entire procedure in this article.
- Chat API URI: The service backend endpoint shown at the end of the
A development container environment is available with all dependencies required to complete this article. You can run the development container in GitHub Codespaces (in a browser) or locally using Visual Studio Code.
- GitHub account
Open development environment
Begin now with a development environment that has all the dependencies installed to complete this article. You should arrange your monitor workspace so you can see both this documentation and the development environment at the same time.
This article was tested with the switzerlandnorth region for the evaluation deployment.
GitHub Codespaces runs a development container managed by GitHub with Visual Studio Code for the Web as the user interface. For the most straightforward development environment, use GitHub Codespaces so that you have the correct developer tools and dependencies preinstalled to complete this article.
Important
All GitHub accounts can use Codespaces for up to 60 hours free each month with 2 core instances. For more information, see GitHub Codespaces monthly included storage and core hours.
Start the process to create a new GitHub Codespace on the
mainbranch of theAzure-Samples/ai-rag-chat-evaluatorGitHub repository.Right-click on the following button, and select Open link in new window in order to have both the development environment and the documentation available at the same time.

On the Create codespace page, review the codespace configuration settings and then select Create new codespace
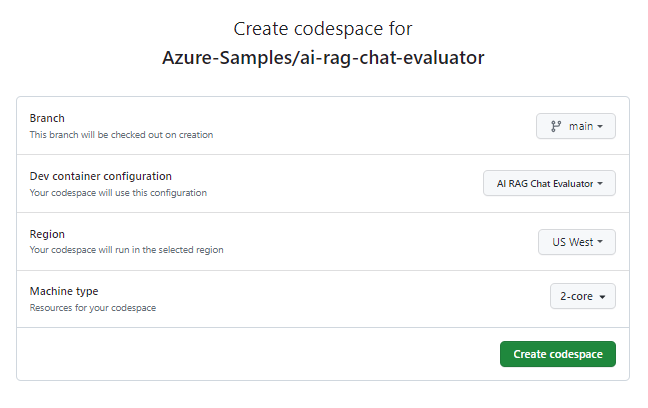
Wait for the codespace to start. This startup process can take a few minutes.
In the terminal at the bottom of the screen, sign in to Azure with the Azure Developer CLI.
azd auth login --use-device-codeCopy the code from the terminal and then paste it into a browser. Follow the instructions to authenticate with your Azure account.
Provision the required Azure resource, Azure OpenAI, for the evaluations app.
azd upThis doesn't deploy the evaluations app, but it does create the Azure OpenAI resource with a GPT-4 deployment that's required to run the evaluations locally in the development environment.
The remaining tasks in this article take place in the context of this development container.
The name of the GitHub repository is shown in the search bar. This visual indicator helps you distinguish between this evaluations app from the chat app. This
ai-rag-chat-evaluatorrepo is referred to as the Evaluations app in this article.

Prepare environment values and configuration information
Update the environment values and configuration information with the information you gathered during Prerequisites for the evaluations app.
Use the following command to get the Evaluations app resource information into a
.envfile:azd env get-values > .envAdd the following values from the chat app for its Azure AI Search instance to the
.env, which you gathered in the prerequisites section:AZURE_SEARCH_SERVICE="<service-name>" AZURE_SEARCH_INDEX="<index-name>"The
AZURE_SEARCH_KEYvalue is the query key for the Azure AI Search instance.Create a new file named
my_config.jsonand copy the following content into it:{ "testdata_path": "my_input/qa.jsonl", "results_dir": "my_results/experiment<TIMESTAMP>", "target_url": "http://localhost:50505/chat", "target_parameters": { "overrides": { "semantic_ranker": false, "prompt_template": "<READFILE>my_input/prompt_refined.txt" } } }The evaluation script creates the
my_resultsfolder.Change the
target_urlto the URI value of your chat app, which you gathered in the prerequisites section. The chat app must conform to the chat protocol. The URI has the following formathttps://CHAT-APP-URL/chat. Make sure the protocol and thechatroute are part of the URI.
Generate sample data
In order to evaluate new answers, they must be compared to a "ground truth" answer, which is the ideal answer for a particular question. Generate questions and answers from documents stored in Azure AI Search for the chat app.
Copy the
example_inputfolder into a new folder namedmy_input.In a terminal, run the following command to generate the sample data:
python3 -m scripts generate --output=my_input/qa.jsonl --numquestions=14 --persource=2
The question/answer pairs are generated and stored in my_input/qa.jsonl (in JSONL format) as input to the evaluator used in the next step. For a production evaluation, you would generate more QA pairs, more than 200 for this dataset.
Note
The few number of questions and answers per source is meant to allow you to quickly complete this procedure. It isn't meant to be a production evaluation which should have more questions and answers per source.
Run first evaluation with a refined prompt
Edit the
my_config.jsonconfig file properties:Property New value results_dir my_results/experiment_refinedprompt_template <READFILE>my_input/prompt_refined.txtThe refined prompt is specific about the subject domain.
If there isn't enough information below, say you don't know. Do not generate answers that don't use the sources below. If asking a clarifying question to the user would help, ask the question. Use clear and concise language and write in a confident yet friendly tone. In your answers ensure the employee understands how your response connects to the information in the sources and include all citations necessary to help the employee validate the answer provided. For tabular information return it as an html table. Do not return markdown format. If the question is not in English, answer in the language used in the question. Each source has a name followed by colon and the actual information, always include the source name for each fact you use in the response. Use square brackets to reference the source, e.g. [info1.txt]. Don't combine sources, list each source separately, e.g. [info1.txt][info2.pdf].In a terminal, run the following command to run the evaluation:
python3 -m scripts evaluate --config=my_config.json --numquestions=14This script created a new experiment folder in
my_results/with the evaluation. The folder contains the results of the evaluation including:File Name Description eval_results.jsonlEach question and answer, along with the GPT metrics for each QA pair. summary.jsonThe overall results, like the average GPT metrics.
Run second evaluation with a weak prompt
Edit the
my_config.jsonconfig file properties:Property New value results_dir my_results/experiment_weakprompt_template <READFILE>my_input/prompt_weak.txtThat weak prompt has no context about the subject domain:
You are a helpful assistant.In a terminal, run the following command to run the evaluation:
python3 -m scripts evaluate --config=my_config.json --numquestions=14
Run third evaluation with a specific temperature
Use a prompt which allows for more creativity.
Edit the
my_config.jsonconfig file properties:Existing Property New value Existing results_dir my_results/experiment_ignoresources_temp09Existing prompt_template <READFILE>my_input/prompt_ignoresources.txtNew temperature 0.9The default temperature is 0.7. The higher the temperature, the more creative the answers.
The ignore prompt is short:
Your job is to answer questions to the best of your ability. You will be given sources but you should IGNORE them. Be creative!The config object should like the following except use your own
results_dir:{ "testdata_path": "my_input/qa.jsonl", "results_dir": "my_results/prompt_ignoresources_temp09", "target_url": "https://YOUR-CHAT-APP/chat", "target_parameters": { "overrides": { "temperature": 0.9, "semantic_ranker": false, "prompt_template": "<READFILE>my_input/prompt_ignoresources.txt" } } }In a terminal, run the following command to run the evaluation:
python3 -m scripts evaluate --config=my_config.json --numquestions=14
Review the evaluation results
You have performed three evaluations based on different prompts and app settings. The results are stored in the my_results folder. Review how the results differ based on the settings.
Use the review tool to see the results of the evaluations:
python3 -m review_tools summary my_resultsThe results look something like:

Each value is returned as a number and a percentage.
Use the following table to understand the meaning of the values.
Value Description Groundedness This refers to how well the model's responses are based on factual, verifiable information. A response is considered grounded if it's factually accurate and reflects reality. Relevance This measures how closely the model's responses align with the context or the prompt. A relevant response directly addresses the user's query or statement. Coherence This refers to how logically consistent the model's responses are. A coherent response maintains a logical flow and doesn't contradict itself. Citation This indicates if the answer was returned in the format requested in the prompt. Length This measures the length of the response. The results should indicate all 3 evaluations had high relevance while the
experiment_ignoresources_temp09had the lowest relevance.Select the folder to see the configuration for the evaluation.
Enter Ctrl + C exit the app and return to the terminal.
Compare the answers
Compare the returned answers from the evaluations.
Select two of the evaluations to compare, then use the same review tool to compare the answers:
python3 -m review_tools diff my_results/experiment_refined my_results/experiment_ignoresources_temp09Review the results. Your results may vary.

Enter Ctrl + C exit the app and return to the terminal.
Suggestions for further evaluations
- Edit the prompts in
my_inputto tailor the answers such as subject domain, length, and other factors. - Edit the
my_config.jsonfile to change the parameters such astemperature, andsemantic_rankerand rerun experiments. - Compare different answers to understand how the prompt and question impact the answer quality.
- Generate a separate set of questions and ground truth answers for each document in the Azure AI Search index. Then rerun the evaluations to see how the answers differ.
- Alter the prompts to indicate shorter or longer answers by adding the requirement to the end of the prompt. For example,
Please answer in about 3 sentences.
Clean up resources
Clean up Azure resources
The Azure resources created in this article are billed to your Azure subscription. If you don't expect to need these resources in the future, delete them to avoid incurring more charges.
Run the following Azure Developer CLI command to delete the Azure resources and remove the source code:
azd down --purge
Clean up GitHub Codespaces
Deleting the GitHub Codespaces environment ensures that you can maximize the amount of free per-core hours entitlement you get for your account.
Important
For more information about your GitHub account's entitlements, see GitHub Codespaces monthly included storage and core hours.
Sign into the GitHub Codespaces dashboard (https://github.com/codespaces).
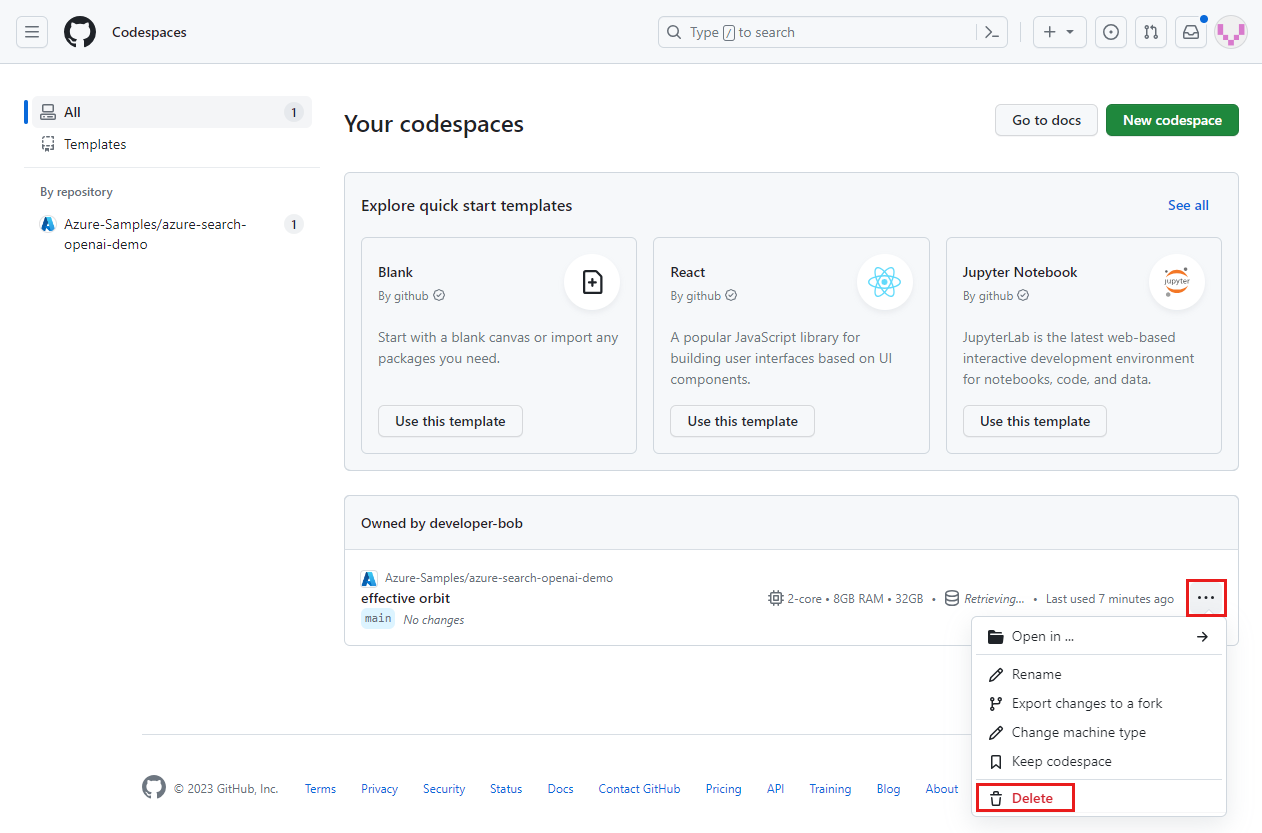
Locate your currently running Codespaces sourced from the
Azure-Samples/ai-rag-chat-evaluatorGitHub repository.
Open the context menu for the codespace and then select Delete.
Return to the chat app article to clean up those resources.
Next steps
- Evaluations repository
- Enterprise chat app GitHub repository
- Build a chat app with Azure OpenAI best practice solution architecture
- Access control in Generative AI apps with Azure AI Search
- Build an Enterprise ready OpenAI solution with Azure API Management
- Outperforming vector search with hybrid retrieval and ranking capabilities
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for