Troubleshoot replication latency in Azure Database for MySQL - Flexible Server
APPLIES TO:  Azure Database for MySQL - Single Server
Azure Database for MySQL - Flexible Server
Azure Database for MySQL - Single Server
Azure Database for MySQL - Flexible Server
Important
Azure Database for MySQL single server is on the retirement path. We strongly recommend that you upgrade to Azure Database for MySQL flexible server. For more information about migrating to Azure Database for MySQL flexible server, see What's happening to Azure Database for MySQL Single Server?
Note
This article references a term that Microsoft no longer uses. When the term is removed from the software, we'll remove it from this article.
The read replica feature allows you to replicate data from an Azure Database for MySQL server to a read-only replica server. You can scale out workloads by routing read and reporting queries from the application to replica servers. This setup reduces the pressure on the source server and improves overall performance and latency of the application as it scales.
Replicas are updated asynchronously by using the MySQL engine's native binary log (binlog) file position-based replication technology. For more information, see MySQL binlog file position-based replication configuration overview.
The replication lag on the secondary read replicas depends several factors. These factors include but aren't limited to:
- Network latency.
- Transaction volume on the source server.
- Compute tier of the source server and secondary read replica server.
- Queries running on the source server and secondary server.
In this article, you'll learn how to troubleshoot replication latency in Azure Database for MySQL. You'll also get a better idea of some common causes of increased replication latency on replica servers.
Note
This article contains references to the term slave, a term that Microsoft no longer uses. When the term is removed from the software, we'll remove it from this article.
Replication concepts
When a binary log is enabled, the source server writes committed transactions into the binary log. The binary log is used for replication. It's turned on by default for all newly provisioned servers that support up to 16 TB of storage. On replica servers, two threads run on each replica server. One thread is the IO thread, and the other is the SQL thread:
- The IO thread connects to the source server and requests updated binary logs. This thread receives the binary log updates. Those updates are saved on a replica server, in a local log called the relay log.
- The SQL thread reads the relay log and then applies the data changes on replica servers.
Monitoring replication latency
Azure Database for MySQL provides the metric for replication lag in seconds in Azure Monitor. This metric is available only on read replica servers. It's calculated by the seconds_behind_master metric that's available in MySQL.
To understand the cause of increased replication latency, connect to the replica server by using MySQL Workbench or Azure Cloud Shell. Then run following command.
Note
In your code, replace the example values with your replica server name and admin username. The admin username requires @\<servername> for Azure Database for MySQL.
mysql --host=myreplicademoserver.mysql.database.azure.com --user=myadmin@mydemoserver -p
Here's how the experience looks in the Cloud Shell terminal:
Requesting a Cloud Shell.Succeeded.
Connecting terminal...
Welcome to Azure Cloud Shell
Type "az" to use Azure CLI
Type "help" to learn about Cloud Shell
user@Azure:~$mysql -h myreplicademoserver.mysql.database.azure.com -u myadmin@mydemoserver -p
Enter password:
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 64796
Server version: 5.6.42.0 Source distribution
Copyright (c) 2000, 2020, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql>
In the same Cloud Shell terminal, run the following command:
mysql> SHOW SLAVE STATUS;
Here's a typical output:
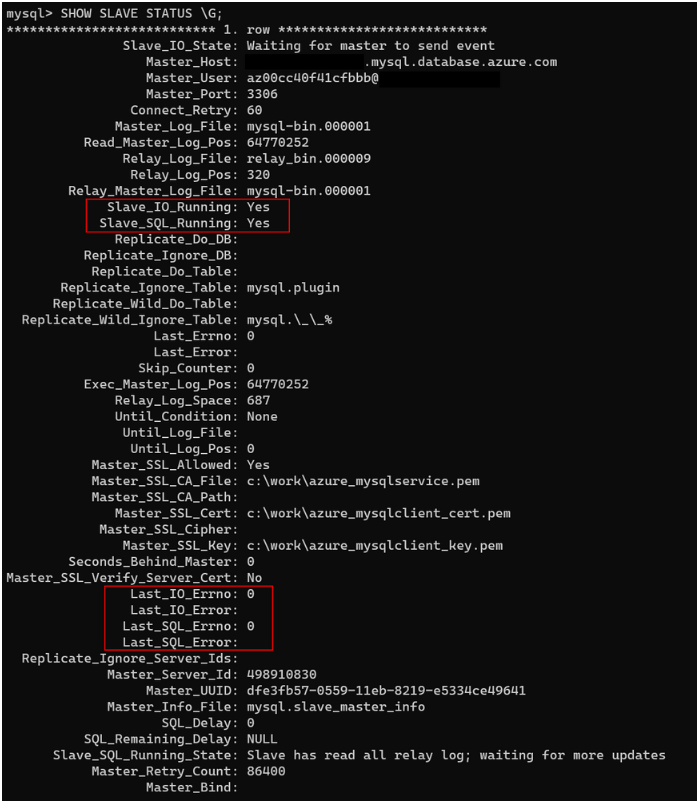
The output contains numerous information. Normally, you need to focus on only the rows that the following table describes.
| Metric | Description |
|---|---|
| Slave_IO_State | Represents the current status of the IO thread. Normally, the status is "Waiting for master to send event" if the source (master) server is synchronizing. A status such as "Connecting to master" indicates that the replica lost the connection to the source server. Make sure the source server is running, or check to see whether a firewall is blocking the connection. |
| Master_Log_File | Represents the binary log file to which the source server is writing. |
| Read_Master_Log_Pos | Indicates where the source server is writing in the binary log file. |
| Relay_Master_Log_File | Represents the binary log file that the replica server is reading from the source server. |
| Slave_IO_Running | Indicates whether the IO thread is running. The value should be Yes. If the value is NO, then the replication is likely broken. |
| Slave_SQL_Running | Indicates whether the SQL thread is running. The value should be Yes. If the value is NO, then the replication is likely broken. |
| Exec_Master_Log_Pos | Indicates the position of the Relay_Master_Log_File that the replica is applying. If there's latency, then this position sequence should be smaller than Read_Master_Log_Pos. |
| Relay_Log_Space | Indicates the total combined size of all existing relay log files. You can check the upper limit size by querying SHOW GLOBAL VARIABLES like relay_log_space_limit. |
| Seconds_Behind_Master | Displays replication latency in seconds. |
| Last_IO_Errno | Displays the IO thread error code, if any. For more information about these codes, see the MySQL server error message reference. |
| Last_IO_Error | Displays the IO thread error message, if any. |
| Last_SQL_Errno | Displays the SQL thread error code, if any. For more information about these codes, see the MySQL server error message reference. |
| Last_SQL_Error | Displays the SQL thread error message, if any. |
| Slave_SQL_Running_State | Indicates the current SQL thread status. In this state, System lock is normal. It's also normal to see a status of Waiting for dependent transaction to commit. This status indicates that the replica is waiting for other SQL worker threads to update committed transactions. |
If Slave_IO_Running is Yes and Slave_SQL_Running is Yes, then the replication is running fine.
Next, check Last_IO_Errno, Last_IO_Error, Last_SQL_Errno, and Last_SQL_Error. These fields display the error number and error message of the most-recent error that caused the SQL thread to stop. An error number of 0 and an empty message means there's no error. Investigate any nonzero error value by checking the error code in the MySQL server error message reference.
Common scenarios for high replication latency
The following sections address scenarios in which high replication latency is common.
Network latency or high CPU consumption on the source server
If you see the following values, then replication latency is likely caused by high network latency or high CPU consumption on the source server.
Slave_IO_State: Waiting for master to send event
Master_Log_File: the binary file sequence is larger then Relay_Master_Log_File, e.g. mysql-bin.00020
Relay_Master_Log_File: the file sequence is smaller than Master_Log_File, e.g. mysql-bin.00010
In this case, the IO thread is running and is waiting on the source server. The source server has already written to binary log file number 20. The replica has received only up to file number 10. The primary factors for high replication latency in this scenario are network speed or high CPU utilization on the source server.
In Azure, network latency within a region can typically be measured milliseconds. Across regions, latency ranges from milliseconds to seconds.
In most cases, the connection delay between IO threads and the source server is caused by high CPU utilization on the source server. The IO threads are processed slowly. You can detect this problem by using Azure Monitor to check CPU utilization and the number of concurrent connections on the source server.
If you don't see high CPU utilization on the source server, the problem might be network latency. If network latency is suddenly abnormally high, check the Azure status page for known issues or outages.
Heavy bursts of transactions on the source server
If you see the following values, then a heavy burst of transactions on the source server is likely causing the replication latency.
Slave_IO_State: Waiting for the slave SQL thread to free enough relay log space
Master_Log_File: the binary file sequence is larger then Relay_Master_Log_File, e.g. mysql-bin.00020
Relay_Master_Log_File: the file sequence is smaller then Master_Log_File, e.g. mysql-bin.00010
The output shows that the replica can retrieve the binary log behind the source server. But the replica IO thread indicates that the relay log space is full already.
Network speed isn't causing the delay. The replica is trying to catch up. But the updated binary log size exceeds the upper limit of the relay log space.
To troubleshoot this issue, enable the slow query log on the source server. Use slow query logs to identify long-running transactions on the source server. Then tune the identified queries to reduce the latency on the server.
Replication latency of this sort is commonly caused by the data load on the source server. When source servers have weekly or monthly data loads, replication latency is unfortunately unavoidable. The replica servers eventually catch up after the data load on the source server finishes.
Slowness on the replica server
If you observe the following values, then the problem might be on the replica server.
Slave_IO_State: Waiting for master to send event
Master_Log_File: The binary log file sequence equals to Relay_Master_Log_File, e.g. mysql-bin.000191
Read_Master_Log_Pos: The position of master server written to the above file is larger than Relay_Log_Pos, e.g. 103978138
Relay_Master_Log_File: mysql-bin.000191
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Exec_Master_Log_Pos: The position of slave reads from master binary log file is smaller than Read_Master_Log_Pos, e.g. 13468882
Seconds_Behind_Master: There is latency and the value here is greater than 0
In this scenario, the output shows that both the IO thread and the SQL thread are running well. The replica reads the same binary log file that the source server writes. However, some latency on the replica server reflects the same transaction from the source server.
The following sections describe common causes of this kind of latency.
No primary key or unique key on a table
Azure Database for MySQL uses row-based replication. The source server writes events to the binary log, recording changes in individual table rows. The SQL thread then replicates those changes to the corresponding table rows on the replica server. When a table lacks a primary key or unique key, the SQL thread scans all rows in the target table to apply the changes. This scan can cause replication latency.
In MySQL, the primary key is an associated index that ensures fast query performance because it can't include NULL values. If you use the InnoDB storage engine, the table data is physically organized to do ultra-fast lookups and sorts based on the primary key.
We recommend that you add a primary key on tables in the source server before you create the replica server. Add primary keys on the source server and then re-create read replicas to help improve replication latency.
Use the following query to find out which tables are missing a primary key on the source server:
select tab.table_schema as database_name, tab.table_name
from information_schema.tables tab left join
information_schema.table_constraints tco
on tab.table_schema = tco.table_schema
and tab.table_name = tco.table_name
and tco.constraint_type = 'PRIMARY KEY'
where tco.constraint_type is null
and tab.table_schema not in('mysql', 'information_schema', 'performance_schema', 'sys')
and tab.table_type = 'BASE TABLE'
order by tab.table_schema, tab.table_name;
Long-running queries on the replica server
The workload on the replica server can make the SQL thread lag behind the IO thread. Long-running queries on the replica server are one of the common causes of high replication latency. To troubleshoot this problem, enable the slow query log on the replica server.
Slow queries can increase resource consumption or slow down the server so that the replica can't catch up with the source server. In this scenario, tune the slow queries. Faster queries prevent blockage of the SQL thread and improve replication latency significantly.
DDL queries on the source server
On the source server, a data definition language (DDL) command like ALTER TABLE can take a long time. While the DDL command is running, thousands of other queries might be running in parallel on the source server.
When the DDL is replicated, to ensure database consistency, the MySQL engine runs the DDL in a single replication thread. During this task, all other replicated queries are blocked and must wait until the DDL operation finishes on the replica server. Even online DDL operations cause this delay. DDL operations increase replication latency.
If you enabled the slow query log on the source server, you can detect this latency problem by checking for a DDL command that ran on the source server. Through index dropping, renaming, and creating, you can use the INPLACE algorithm for the ALTER TABLE. You might need to copy the table data and rebuild the table.
Typically, concurrent DML is supported for the INPLACE algorithm. But you can briefly take an exclusive metadata lock on the table when you prepare and run the operation. So for the CREATE INDEX statement, you can use the clauses ALGORITHM and LOCK to influence the method for table copying and the level of concurrency for reading and writing. You can still prevent DML operations by adding a FULLTEXT index or SPATIAL index.
The following example creates an index by using ALGORITHM and LOCK clauses.
ALTER TABLE table_name ADD INDEX index_name (column), ALGORITHM=INPLACE, LOCK=NONE;
Unfortunately, for a DDL statement that requires a lock, you can't avoid replication latency. To reduce the potential effects, do these types of DDL operations during off-peak hours, for instance during the night.
Downgraded replica server
In Azure Database for MySQL, read replicas use the same server configuration as the source server. You can change the replica server configuration after it has been created.
If the replica server is downgraded, the workload can consume more resources, which in turn can lead to replication latency. To detect this problem, use Azure Monitor to check the CPU and memory consumption of the replica server.
In this scenario, we recommend that you keep the replica server's configuration at values equal to or greater than the values of the source server. This configuration allows the replica to keep up with the source server.
Improving replication latency by tuning the source server parameters
In Azure Database for MySQL, by default, replication is optimized to run with parallel threads on replicas. When high-concurrency workloads on the source server cause the replica server to fall behind, you can improve the replication latency by configuring the parameter binlog_group_commit_sync_delay on the source server.
The binlog_group_commit_sync_delay parameter controls how many microseconds the binary log commit waits before synchronizing the binary log file. The benefit of this parameter is that instead of immediately applying every committed transaction, the source server sends the binary log updates in bulk. This delay reduces IO on the replica and helps improve performance.
It might be useful to set the binlog_group_commit_sync_delay parameter to 1000 or so. Then monitor the replication latency. Set this parameter cautiously, and use it only for high-concurrency workloads.
Important
In replica server, binlog_group_commit_sync_delay parameter is recommended to be 0. This is recommended because unlike source server, the replica server won't have high-concurrency and increasing the value for binlog_group_commit_sync_delay on replica server could inadvertently cause replication lag to increase.
For low-concurrency workloads that include many singleton transactions, the binlog_group_commit_sync_delay setting can increase latency. Latency can increase because the IO thread waits for bulk binary log updates even if only a few transactions are committed.
Advanced Troubleshooting Options
If using the show slave status command doesn't provide enough information to troubleshoot replication latency, try viewing these additional options for learning about which processes are active or waiting.
View the threads table
The performance_schema.threads table shows the process state. A process with the state Waiting for lock_type lock indicates that there’s a lock on one of the tables, preventing the replication thread from updating the table.
SELECT name, processlist_state, processlist_time FROM performance_schema.threads WHERE name LIKE '%slave%';
For more information, see General Thread States.
View the replication_connection_status table
The performance_schema.replication_connection_status table shows the current status of the replication I/O thread that handles the replica's connection to the source, and it changes more frequently. The table contains values that vary during the connection.
SELECT * FROM performance_schema.replication_connection_status;
View the replication_applier_status_by_worker table
The performance_schema.replication_applier_status_by_worker table shows the status of the worker threads, Last seen transaction along with last error number and message, which help you find the transaction having issue and identify the root cause.
You can run the below commands in the Data-in replication to skip errors or transactions:
az_replication_skip_counter
or
az_replication_skip_gtid_transaction
SELECT * FROM performance_schema.replication_applier_status_by_worker;
View the SHOW RELAYLOG EVENTS statement
The show relaylog events statement shows the events in the relay log of a replica.
· For GITD based replication (Read replica), the statement shows GTID transaction and binlog file and its position, you can use mysqlbinlog to get contents and statements being run. · For MySQL binlog position replication (used for Data-in replication), it shows statements being run, which will help to know on which table transactions are being run
Check the InnoDB Standard Monitor and Lock Monitor Output
You can also try checking the InnoDB Standard Monitor and Lock Monitor Output to help in resolving locks and deadlocks and minimize replication lag. The Lock Monitor is the same as the Standard Monitor except that it includes additional lock information. To view this additional lock and deadlock information, run the show engine innodb status\G command.
Next steps
Check out the MySQL binlog replication overview.
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for