What is data warehousing on Azure Databricks?
Data warehousing refers to collecting and storing data from multiple sources so it can be quickly accessed for business insights and reporting. This article contains key concepts for building a data warehouse in your data lakehouse.
Data warehousing in your lakehouse
The lakehouse architecture and Databricks SQL bring cloud data warehousing capabilities to your data lakes. Using familiar data structures, relations, and management tools, you can model a highly-performant, cost-effective data warehouse that runs directly on your data lake. For more information, see What is a data lakehouse?
As with a traditional data warehouse, you model data according to business requirements and then serve it to your end users for analytics and reports. Unlike a traditional data warehouse, you can avoid siloing your business analytics data or creating redundant copies that quickly become stale.
Building a data warehouse inside your lakehouse lets you bring all your data into a single system and lets you take advantage of features such as Unity Catalog and Delta Lake.
Unity Catalog adds a unified governance model so that you can secure and audit data access and provide lineage information on downstream tables. Delta Lake adds ACID transactions and schema evolution, among other powerful tools for keeping your data reliable, scalable, and high-quality.
What is Databricks SQL?
Note
Databricks SQL Serverless is not available in Azure China. Databricks SQL is not available in Azure Government regions.
Databricks SQL is the collection of services that bring data warehousing capabilities and performance to your existing data lakes. Databricks SQL supports open formats and standard ANSI SQL. An in-platform SQL editor and dashboarding tools allow team members to collaborate with other Databricks users directly in the workspace. Databricks SQL also integrates with a variety of tools so that analysts can author queries and dashboards in their favorite environments without adjusting to a new platform.
Databricks SQL provides general compute resources that are executed against the tables in the lakehouse. Databricks SQL is powered by SQL warehouses, offering scalable SQL compute resources decoupled from storage.
See What is a SQL warehouse? for more information on SQL Warehouse defaults and options.
Databricks SQL integrates with Unity Catalog so that you can discover, audit, and govern data assets from one place. To learn more, see What is Unity Catalog?
Data modeling on Azure Databricks
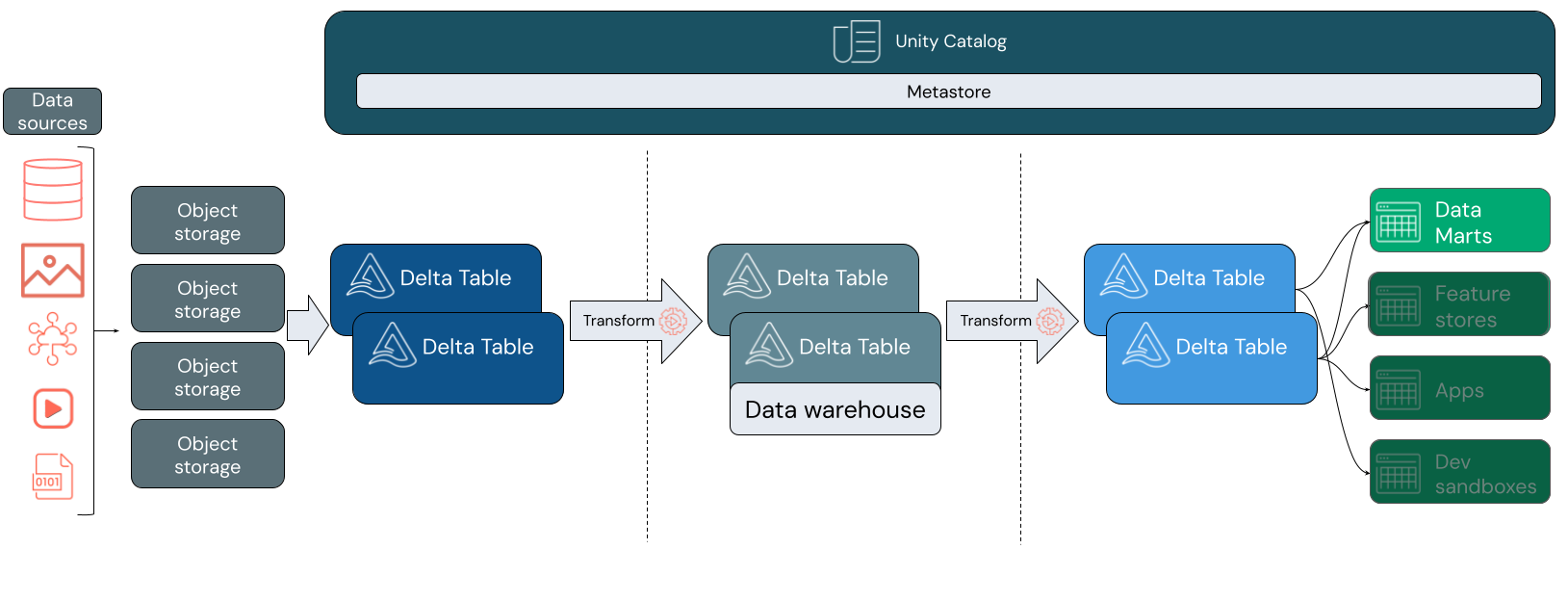
A lakehouse supports a variety of modeling styles. The following image shows how data is curated and modeled as it moves through different layers of a lakehouse.

Medallion architecture
The medallion architecture is a data design pattern that describes a series of incrementally refined data layers that provide a basic structure in the lakehouse. The bronze, silver, and gold layers signify increasing data quality at each level, with gold representing the highest quality. For more information, see What is the medallion lakehouse architecture?.
Inside a lakehouse, each layer can contain one or more tables. The data warehouse is modeled at the silver layer and feeds specialized data marts in the gold layer.
Bronze layer
Data can enter your lakehouse in any format and through any combination of batch or steaming transactions. The bronze layer provides the landing space for all of your raw data in its original format. That data is converted to Delta tables.
Silver layer
The silver layer brings the data from different sources together. For the part of the business that focuses on data science and machine learning applications, this is where you start to curate meaningful data assets. This process is often marked by a focus on speed and agility.
The silver layer is also where you can carefully integrate data from disparate sources to build a data warehouse in alignment with your existing business processes. Often, this data follows a Third Normal Form (3NF) or Data Vault model. Specifying primary and foreign key constraints allows end users to understand table relationships when using Unity Catalog. Your data warehouse should serve as the single source of truth for your data marts.
The data warehouse itself is schema-on-write and atomic. It is optimized for change, so you can quickly modify the data warehouse to match your current needs when your business processes change or evolve.
Gold layer
The gold layer is the presentation layer, which can contain one or more data marts. Frequently, data marts are dimensional models in the form of a set of related tables that capture a specific business perspective.
The gold layer also houses departmental and data science sandboxes to enable self-service analytics and data science across the enterprise. Providing these sandboxes and their own separate compute clusters prevents the Business teams from creating copies of data outside the lakehouse.
Next step
To learn more about the principles and best practices for implementing and operating a lakehouse using Databricks, see Introduction to the well-architected data lakehouse.
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for