Configure streaming ingestion on your Azure Data Explorer cluster
Article
Streaming ingestion is useful for loading data when you need low latency between ingestion and query. Consider using streaming ingestion in the following scenarios:
Latency of less than a second is required.
To optimize operational processing of many tables where the stream of data into each table is relatively small (a few records per second), but the overall data ingestion volume is high (thousands of records per second).
If the stream of data into each table is high (over 4 GB per hour), consider using queued ingestion.
For code samples based on previous SDK versions, see the archived article.
Choose the appropriate streaming ingestion type
Two streaming ingestion types are supported:
Ingestion type
Description
Data connection
Event Hubs, IoT Hub, and Event Grid data connections can use streaming ingestion, provided it is enabled on the cluster level. The decision to use streaming ingestion is done according to the streaming ingestion policy configured on the target table. For information on managing data connections, see Event Hub, IoT Hub and Event Grid.
Custom ingestion
Custom ingestion requires you to write an application that uses one of the Azure Data Explorer client libraries. Use the information in this topic to configure custom ingestion. You may also find the C# streaming ingestion sample application helpful.
Use the following table to help you choose the ingestion type that's appropriate for your environment:
Criterion
Data connection
Custom Ingestion
Data delay between ingestion initiation and the data available for query
Longer delay
Shorter delay
Development overhead
Fast and easy setup, no development overhead
High development overhead to create an application ingest the data, handle errors, and ensure data consistency
Note
You can manage the process to enable and disable streaming ingestion on your cluster using the Azure portal or programmatically in C#. If you are using C# for your custom application, you may find it more convenient using the programmatic approach.
The main contributors that can impact streaming ingestion are:
VM and cluster size: Streaming ingestion performance and capacity scales with increased VM and cluster sizes. The number of concurrent ingestion requests is limited to six per core. For example, for 16 core SKUs, such as D14 and L16, the maximal supported load is 96 concurrent ingestion requests. For two core SKUs, such as D11, the maximal supported load is 12 concurrent ingestion requests.
Data size limit: The data size limit for a streaming ingestion request is 4 MB. This includes any data created for update policies during the ingestion.
Schema updates: Schema updates, such as creation and modification of tables and ingestion mappings, may take up to five minutes for the streaming ingestion service. For more information see Streaming ingestion and schema changes.
SSD capacity: Enabling streaming ingestion on a cluster, even when data isn't ingested via streaming, uses part of the local SSD disk of the cluster machines for streaming ingestion data and reduces the storage available for hot cache.
To enable streaming ingestion while creating a new Azure Data Explorer cluster, run the following code:
using System.Threading.Tasks;
using Azure;
using Azure.Core;
using Azure.Identity; // Required package Azure.Identity
using Azure.ResourceManager;
using Azure.ResourceManager.Kusto; // Required package Azure.ResourceManager.Kusto
using Azure.ResourceManager.Kusto.Models;
namespace StreamingIngestion;
class Program
{
static async Task Main(string[] args)
{
var appId = "<appId>";
var appKey = "<appKey>";
var appTenant = "<appTenant>";
var subscriptionId = "<subscriptionId>";
var credentials = new ClientSecretCredential(appTenant, appId, appKey);
var resourceManagementClient = new ArmClient(credentials, subscriptionId);
var resourceGroupName = "<resourceGroupName>";
var clusterName = "<clusterName>";
var subscription = await resourceManagementClient.GetDefaultSubscriptionAsync();
var resourceGroup = (await subscription.GetResourceGroupAsync(resourceGroupName)).Value;
var clusters = resourceGroup.GetKustoClusters();
var location = new AzureLocation("<location>");
var skuName = new KustoSkuName("<skuName>");
var skuTier = new KustoSkuTier("<skuTier>");
var clusterData = new KustoClusterData(location, new KustoSku(skuName, skuTier)) { IsStreamingIngestEnabled = true };
await clusters.CreateOrUpdateAsync(WaitUntil.Completed, clusterName, clusterData);
}
}
Enable streaming ingestion on an existing cluster
If you have an existing cluster, you can enable streaming ingestion using the Azure portal or programmatically in C#.
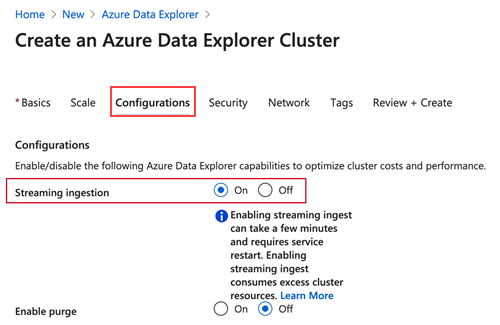
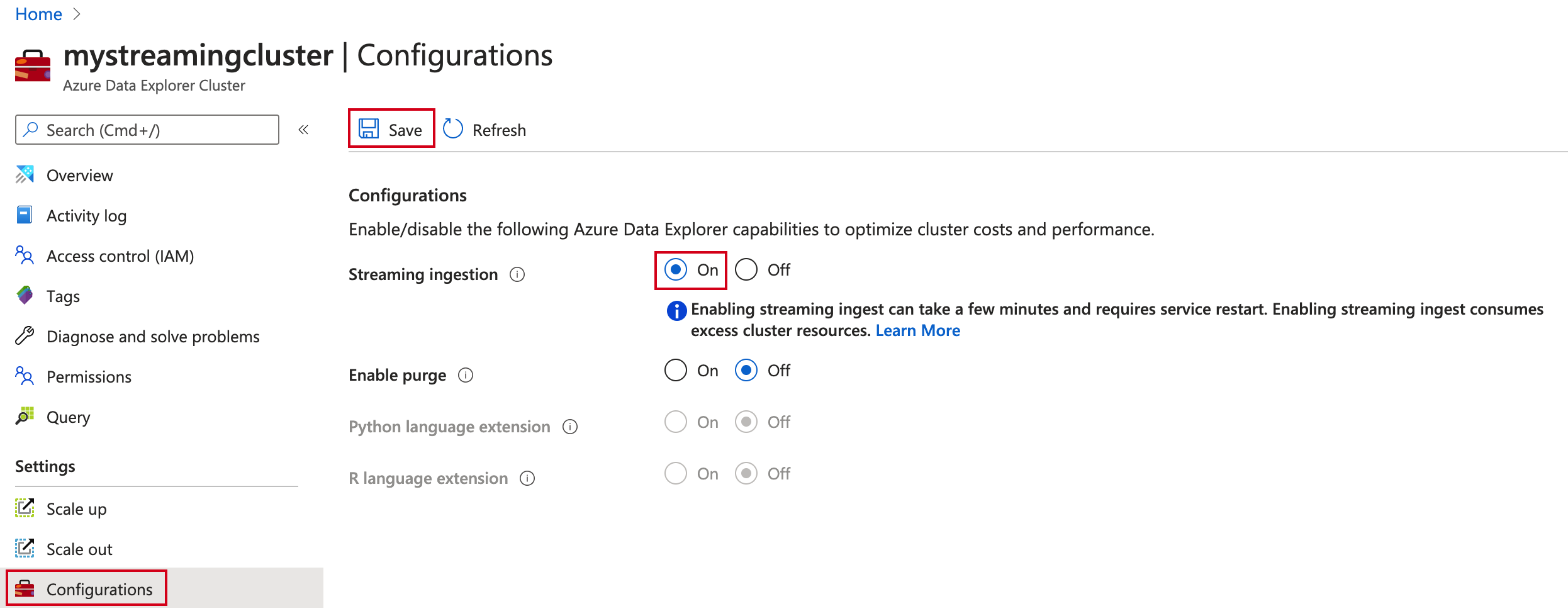
In the Azure portal, go to your Azure Data Explorer cluster.
In Settings, select Configurations.
In the Configurations pane, select On to enable Streaming ingestion.
Select Save.
You can enable streaming ingestion while updating an existing Azure Data Explorer cluster.
using System.Threading.Tasks;
using Azure;
using Azure.Identity; // Required package Azure.Identity
using Azure.ResourceManager;
using Azure.ResourceManager.Kusto; // Required package Azure.ResourceManager.Kusto
using Azure.ResourceManager.Kusto.Models;
namespace StreamingIngestion;
class Program
{
static async Task Main(string[] args)
{
var appId = "<appId>";
var appKey = "<appKey>";
var appTenant = "<appTenant>";
var subscriptionId = "<subscriptionId>";
var credentials = new ClientSecretCredential(appTenant, appId, appKey);
var resourceManagementClient = new ArmClient(credentials, subscriptionId);
var resourceGroupName = "<resourceGroupName>";
var clusterName = "<clusterName>";
var subscription = await resourceManagementClient.GetDefaultSubscriptionAsync();
var resourceGroup = (await subscription.GetResourceGroupAsync(resourceGroupName)).Value;
var cluster = (await resourceGroup.GetKustoClusterAsync(clusterName)).Value;
var clusterPatch = new KustoClusterPatch(cluster.Data.Location) { IsStreamingIngestEnabled = true };
await cluster.UpdateAsync(WaitUntil.Completed, clusterPatch);
}
}
Create a target table and define the policy
Create a table to receive the streaming ingestion data and define its related policy using the Azure portal or programmatically in C#.
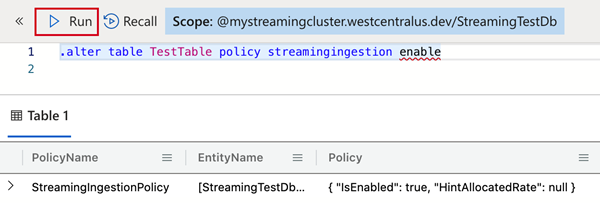
Copy one of the following commands into the Query pane and select Run. This defines the streaming ingestion policy on the table you created or on the database that contains the table.
Tip
A policy that is defined at the database level applies to all existing and future tables in the database. When you enable the policy at the database level, there is no need to enable it per table.
To define the policy on the table you created, use:
using System.IO;
using System.Threading.Tasks;
using Kusto.Data; // Requires Package Microsoft.Azure.Kusto.Data
using Kusto.Data.Common;
using Kusto.Ingest; // Requires Package Microsoft.Azure.Kusto.Ingest
namespace StreamingIngestion;
class Program
{
static async Task Main(string[] args)
{
var clusterPath = "https://<clusterName>.<region>.kusto.windows.net";
var appId = "<appId>";
var appKey = "<appKey>";
var appTenant = "<appTenant>";
// Create Kusto connection string with App Authentication
var connectionStringBuilder = new KustoConnectionStringBuilder(clusterPath)
.WithAadApplicationKeyAuthentication(
applicationClientId: appId,
applicationKey: appKey,
authority: appTenant
);
// Create a disposable client that will execute the ingestion
using var client = KustoIngestFactory.CreateStreamingIngestClient(connectionStringBuilder);
// Ingest from a compressed file
var fileStream = File.Open("MyFile.gz", FileMode.Open);
// Initialize client properties
var ingestionProperties = new KustoIngestionProperties(databaseName: "<databaseName>", tableName: "<tableName>");
// Create source options
var sourceOptions = new StreamSourceOptions { CompressionType = DataSourceCompressionType.GZip, };
// Ingest from stream
await client.IngestFromStreamAsync(fileStream, ingestionProperties, sourceOptions);
}
}
import (
"context"
"github.com/Azure/azure-kusto-go/kusto"
"github.com/Azure/azure-kusto-go/kusto/ingest"
"github.com/Azure/go-autorest/autorest/azure/auth"
)
func ingest() {
clusterPath := "https://<clusterName>.<region>.kusto.windows.net"
appId := "<appId>"
appKey := "<appKey>"
appTenant := "<appTenant>"
dbName := "<dbName>"
tableName := "<tableName>"
mappingName := "<mappingName>" // Optional, can be nil
// Creates a Kusto Authorizer using your client identity, secret, and tenant identity.
// You may also uses other forms of authorization, see GoDoc > Authorization type.
// auth package is: "github.com/Azure/go-autorest/autorest/azure/auth"
authorizer := kusto.Authorization{
Config: auth.NewClientCredentialsConfig(appId, appKey, appTenant),
}
// Create a client
client, err := kusto.New(clusterPath, authorizer)
if err != nil {
panic("add error handling")
}
// Create an ingestion instance
// Pass the client, the name of the database, and the name of table you wish to ingest into.
in, err := ingest.New(client, dbName, tableName)
if err != nil {
panic("add error handling")
}
// Go currently only supports streaming from a byte array with a maximum size of 4 MB.
jsonEncodedData := []byte("{\"a\": 1, \"b\": 10}\n{\"a\": 2, \"b\": 20}")
// Ingestion from a stream commits blocks of fully formed data encodes (JSON, AVRO, ...) into Kusto:
if err := in.Stream(context.Background(), jsonEncodedData, ingest.JSON, mappingName); err != nil {
panic("add error handling")
}
}
import com.microsoft.azure.kusto.data.auth.ConnectionStringBuilder;
import com.microsoft.azure.kusto.ingest.IngestClient;
import com.microsoft.azure.kusto.ingest.IngestClientFactory;
import com.microsoft.azure.kusto.ingest.IngestionProperties;
import com.microsoft.azure.kusto.ingest.result.OperationStatus;
import com.microsoft.azure.kusto.ingest.source.CompressionType;
import com.microsoft.azure.kusto.ingest.source.StreamSourceInfo;
import java.io.FileInputStream;
import java.io.InputStream;
public class FileIngestion {
public static void main(String[] args) throws Exception {
String clusterPath = "https://<clusterName>.<region>.kusto.windows.net";
String appId = "<appId>";
String appKey = "<appKey>";
String appTenant = "<appTenant>";
String dbName = "<dbName>";
String tableName = "<tableName>";
// Build connection string and initialize
ConnectionStringBuilder csb =
ConnectionStringBuilder.createWithAadApplicationCredentials(
clusterPath,
appId,
appKey,
appTenant
);
// Initialize client and its properties
IngestClient client = IngestClientFactory.createClient(csb);
IngestionProperties ingestionProperties =
new IngestionProperties(
dbName,
tableName
);
// Ingest from a compressed file
// Create Source info
InputStream zipInputStream = new FileInputStream("MyFile.gz");
StreamSourceInfo zipStreamSourceInfo = new StreamSourceInfo(zipInputStream);
// If the data is compressed
zipStreamSourceInfo.setCompressionType(CompressionType.gz);
// Ingest from stream
OperationStatus status = client.ingestFromStream(zipStreamSourceInfo, ingestionProperties).getIngestionStatusCollection().get(0).status;
}
}
Disable streaming ingestion on your cluster
Warning
Disabling streaming ingestion may take a few hours.
Before disabling streaming ingestion on your Azure Data Explorer cluster, drop the streaming ingestion policy from all relevant tables and databases. The removal of the streaming ingestion policy triggers data rearrangement inside your Azure Data Explorer cluster. The streaming ingestion data is moved from the initial storage to permanent storage in the column store (extents or shards). This process can take between a few seconds to a few hours, depending on the amount of data in the initial storage.
Drop the streaming ingestion policy
You can drop the streaming ingestion policy using the Azure portal or programmatically in C#.
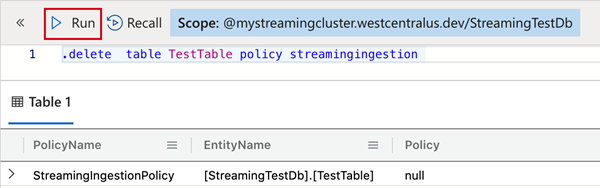
In the Azure portal, go to your Azure Data Explorer cluster and select Query.
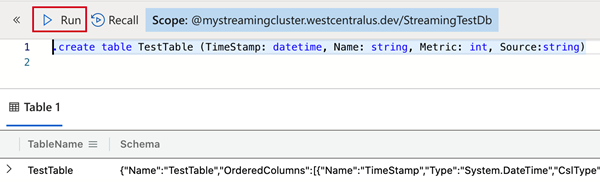
To drop the streaming ingestion policy from the table, copy the following command into Query pane and select Run.
.delete table TestTable policy streamingingestion
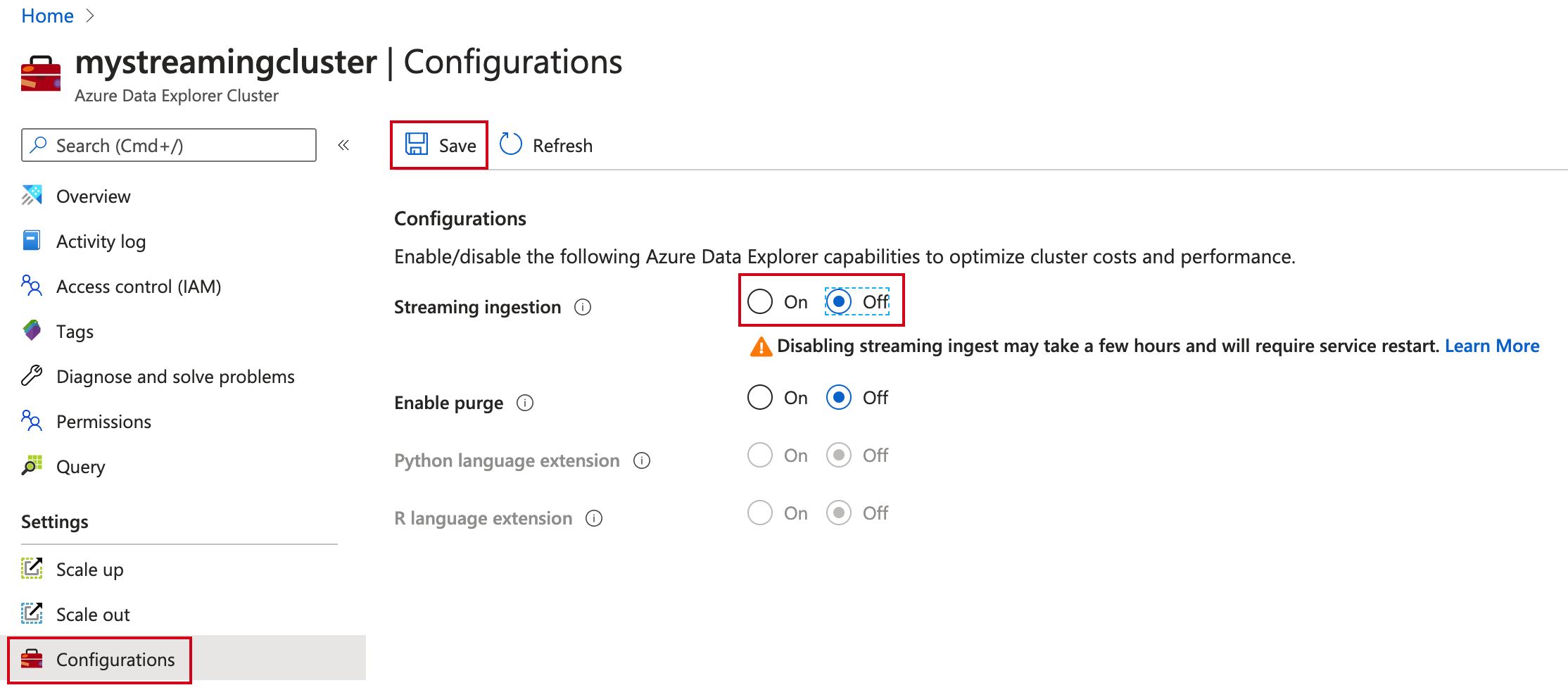
In Settings, select Configurations.
In the Configurations pane, select Off to disable Streaming ingestion.
Select Save.
To drop the streaming ingestion policy from the table, run the following code:
using System.Threading.Tasks;
using Kusto.Data; // Requires Package Microsoft.Azure.Kusto.Data
using Kusto.Data.Common;
using Kusto.Data.Net.Client;
namespace StreamingIngestion;
class Program
{
static async Task Main(string[] args)
{
var clusterPath = "https://<clusterName>.<region>.kusto.windows.net";
var appId = "<appId>";
var appKey = "<appKey>";
var appTenant = "<appTenant>";
// Create Kusto connection string with App Authentication
var connectionStringBuilder = new KustoConnectionStringBuilder(clusterPath)
.WithAadApplicationKeyAuthentication(
applicationClientId: appId,
applicationKey: appKey,
authority: appTenant
);
using var client = KustoClientFactory.CreateCslAdminProvider(connectionStringBuilder);
var tablePolicyDropCommand = CslCommandGenerator.GenerateTableStreamingIngestionPolicyDropCommand("<dbName>", "<tableName>");
await client.ExecuteControlCommandAsync(tablePolicyDropCommand);
}
}
To disable streaming ingestion on your cluster, run the following code:
using System.Threading.Tasks;
using Azure;
using Azure.Identity; // Required package Azure.Identity
using Azure.ResourceManager;
using Azure.ResourceManager.Kusto; // Required package Azure.ResourceManager.Kusto
using Azure.ResourceManager.Kusto.Models;
namespace StreamingIngestion;
class Program
{
static async Task Main(string[] args)
{
var appId = "<appId>";
var appKey = "<appKey>";
var appTenant = "<appTenant>";
var subscriptionId = "<subscriptionId>";
var credentials = new ClientSecretCredential(appTenant, appId, appKey);
var resourceManagementClient = new ArmClient(credentials, subscriptionId);
var resourceGroupName = "<resourceGroupName>";
var clusterName = "<clusterName>";
var subscription = await resourceManagementClient.GetDefaultSubscriptionAsync();
var resourceGroup = (await subscription.GetResourceGroupAsync(resourceGroupName)).Value;
var cluster = (await resourceGroup.GetKustoClusterAsync(clusterName)).Value;
var clusterPatch = new KustoClusterPatch(cluster.Data.Location) { IsStreamingIngestEnabled = false };
await cluster.UpdateAsync(WaitUntil.Completed, clusterPatch);
}
}
Limitations
Data mappings must be pre-created for use in streaming ingestion. Individual streaming ingestion requests don't accommodate inline data mappings.
Extent tags can't be set on the streaming ingestion data.
Update policy. The update policy can reference only the newly ingested data in the source table and not any other data or tables in the database.
When an update policy with a transactional policy fails, the retries will fall back to batch ingestion.
If streaming ingestion is enabled on a cluster used as a leader for follower databases, streaming ingestion must be enabled on the following clusters as well to follow streaming ingestion data. Same applies whether the cluster data is shared via Data Share.
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.