What is Azure Data Catalog?
Important
Azure Data Catalog is being retired on May 15, 2024.
New Azure Data Catalog accounts can no longer be created.
For data catalog features, please use the Microsoft Purview service, which offers unified data governance for your entire data estate.
If you're already using Azure Data Catalog, you'll need to create a migration plan for your organization to move to Microsoft Purview by May 15, 2024.
Azure Data Catalog is a fully managed cloud service that lets users discover the data sources they need and understand the data sources they find. At the same time, Data Catalog helps organizations get more value from their existing investments.
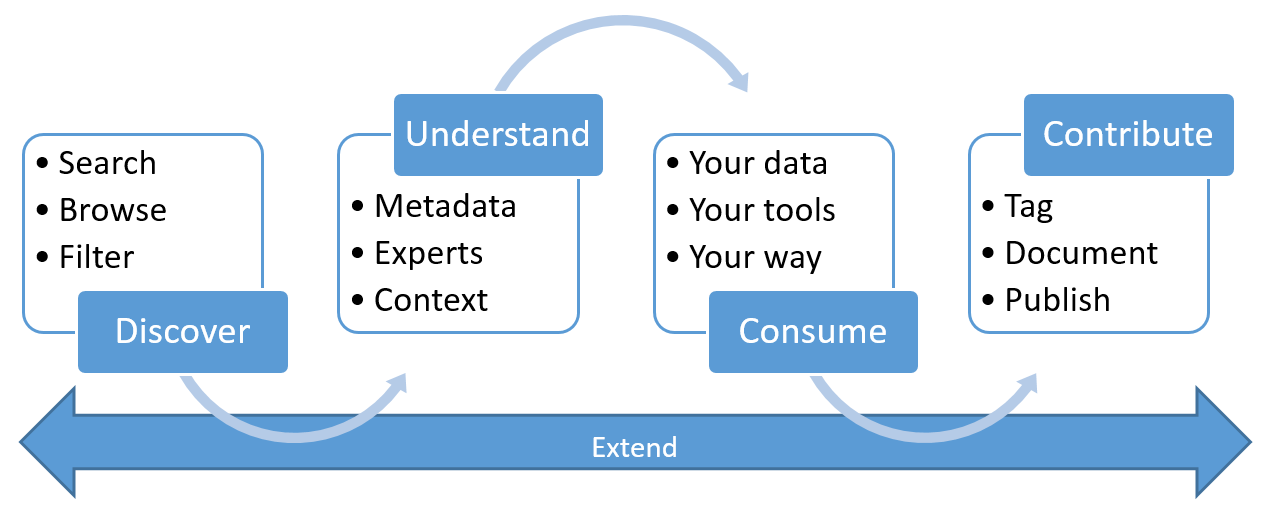
With Data Catalog, any user (analyst, data scientist, or developer) can discover, understand, and consume data sources in their data landscape. Data Catalog includes a crowdsourcing model of metadata and annotations, so everyone can contribute to making data discoverable and useable. It's a single, central place for all of an organization's users to contribute their knowledge and build a community and culture of data.
Discovery challenges for data consumers
Traditionally, discovering enterprise data sources has been an organic process based on tribal knowledge. For companies that want to get the most value from their information assets, this approach presents many challenges:
- Users might not know that a data source exists unless they come into contact with it as part of another process. There's no central location where data sources are registered.
- Unless users know the location of a data source, they can’t connect to the data by using a client application. Data-consumption experiences require users to know the connection string or path.
- Unless users know the location of a data source's documentation, they can’t understand the intended uses of the data. Data sources and documentation might live in various places and be consumed through various experiences.
- If users have questions about an information asset, they must locate the expert or team that's responsible for the data and engage them offline. There's no explicit connection between data and the experts that have perspectives on its use.
- Unless users understand the process for requesting access to the data source, discovering the data source and its documentation still doesn't help them access the data.
Discovery challenges for data producers
Although data consumers face the previously mentioned challenges, users who are responsible for producing and maintaining information assets face challenges of their own:
- Annotating data sources with descriptive metadata is often a lost effort. Client applications typically ignore descriptions that are stored in the data source.
- Creating documentation for data sources is often a lost effort. Keeping documentation in sync with data sources is an ongoing responsibility. Users might lack trust in documentation that's perceived as being out of date.
- Creating and maintaining documentation for data sources is complex and time-consuming. Making that documentation readily available to everyone who uses the data source can be even more so.
- Restricting access to data sources and ensuring that data consumers know how to request access is an ongoing challenge.
When such challenges are combined, they present a significant barrier for companies who want to encourage and promote the use and understanding of enterprise data.
Azure Data Catalog can help
Data Catalog is designed to address these problems and to help enterprises get the most value from their existing information assets. Data Catalog makes data sources easily discoverable and understandable by the users who manage the data.
Data Catalog provides a cloud-based service into which a data source can be registered. The data remains in its existing location, but a copy of its metadata is added to Data Catalog, along with a reference to the data-source location. The metadata is also indexed to make each data source easily discoverable via search and understandable to the users who discover it.
After a data source has been registered, its metadata can then be enriched. The metadata can be added either by the user who registered it or by other users in the enterprise. Any user can annotate a data source by providing descriptions, tags, or other metadata, such as documentation and processes for requesting data source access. This descriptive metadata supplements the structural metadata (such as column names and data types) that's registered from the data source.
Discovering and understanding data sources and their use is the primary purpose of registering the sources. Enterprise users might need data for business intelligence, application development, data science, or any other task where the right data is required. They can use the Data Catalog discovery experience to quickly find data that matches their needs, understand the data to evaluate its fitness for the purpose, and consume the data by opening the data source in their tool of choice.
At the same time, users can contribute to the catalog by tagging, documenting, and annotating data sources that have already been registered. They can also register new data sources, which can then be discovered, understood, and consumed by the community of catalog users.
Learn more about Data Catalog
To learn more about the capabilities of Data Catalog, see:
- How to register data sources
- How to discover data sources
- How to annotate data sources
- How to document data sources
- How to connect to data sources
- How to work with big data
- How to manage data assets
- How to set up the Business Glossary
- Frequently asked questions
Next steps
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for