Retrieval-augmented generation (RAG) provides LLM knowledge
This article describes how retrieval-augmented generation lets LLMs treat your data sources as knowledge without having to train.
LLMs have extensive knowledge bases through training. For most scenarios, you can select an LLM that is designed for your requirements, but those LLMs still require additional training to understand your specific data. Retrieval-augmented generation lets you make your data available to LLMs without training them on it first.
How RAG works
To perform retrieval-augmented generation, you create embeddings for your data along with common questions about it. You can do this on the fly or you can create and store the embeddings by using a vector database solution.
When a user asks a question, the LLM uses your embeddings to compare the user's question to your data and find the most relevant context. This context and the user's question then go to the LLM in a prompt, and the LLM provides a response based on your data.
Basic RAG process
To perform RAG, you must process each data source that you want to use for retrievals. The basic process is as follows:
- Chunk large data into manageable pieces.
- Convert the chunks into a searchable format.
- Store the converted data in a location that allows efficient access. Additionally, it's important to store relevant metadata for citations or references when the LLM provides responses.
- Feed your converted data to LLMs in prompts.
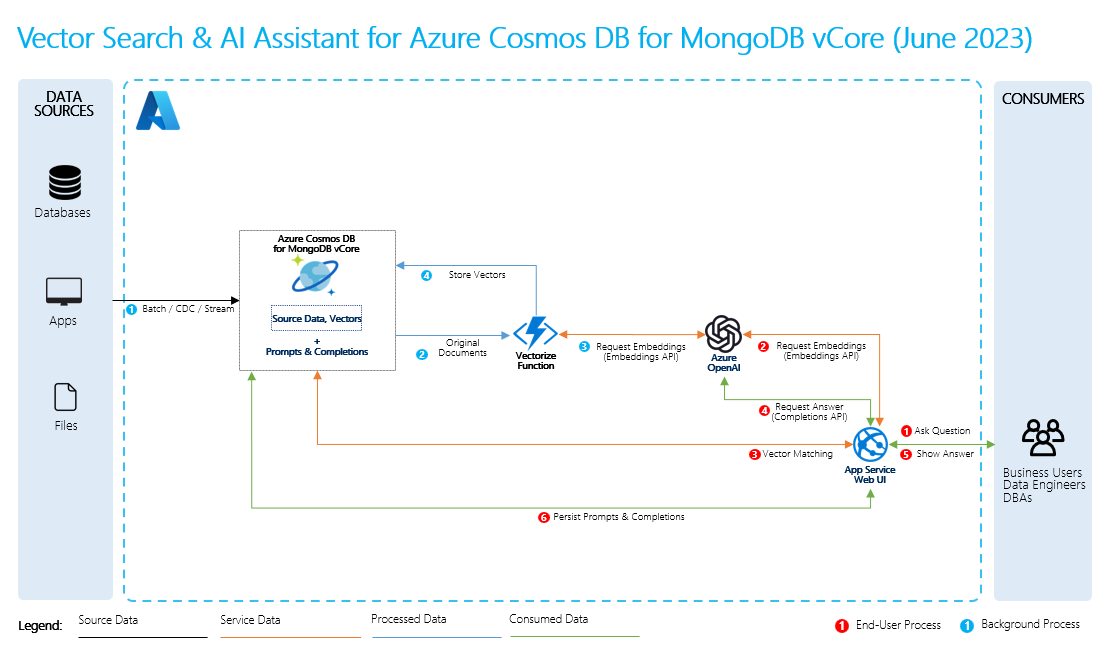
- Source data: This is where your data exists. It could be a file/folder on your machine, a file in cloud storage, an Azure Machine Learning data asset, a Git repository, or an SQL database.
- Data chunking: The data in your source needs to be converted to plain text. For example, word documents or PDFs need to be cracked open and converted to text. The text is then chunked into smaller pieces.
- Converting the text to vectors: These are embeddings. Vectors are numerical representations of concepts converted to number sequences, which make it easy for computers to understand the relationships between those concepts.
- Links between source data and embeddings: This information is stored as metadata on the chunks you created, which are then used to help the LLMs generate citations while generating responses.
Related content
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for