Azure Data Explorer Connector for Apache Spark
Important
This connector can be used in Real-Time Intelligence in Microsoft Fabric. Use the instructions in this article with the following exceptions:
- If required, create databases using the instructions in Create a KQL database.
- If required, create tables using the instructions in Create an empty table.
- Get query or ingestion URIs using the instructions in Copy URI.
- Run queries in a KQL queryset.
Apache Spark is a unified analytics engine for large-scale data processing. Azure Data Explorer is a fast, fully managed data analytics service for real-time analysis on large volumes of data.
The Azure Data Explorer connector for Spark is an open source project that can run on any Spark cluster. It implements data source and data sink for moving data across Azure Data Explorer and Spark clusters. Using Azure Data Explorer and Apache Spark, you can build fast and scalable applications targeting data driven scenarios. For example, machine learning (ML), Extract-Transform-Load (ETL), and Log Analytics. With the connector, Azure Data Explorer becomes a valid data store for standard Spark source and sink operations, such as write, read, and writeStream.
You can write to Azure Data Explorer via queued ingestion or streaming ingestion. Reading from Azure Data Explorer supports column pruning and predicate pushdown, which filters the data in Azure Data Explorer, reducing the volume of transferred data.
Note
For information about working with the Synapse Spark connector for Azure Data Explorer, see Connect to Azure Data Explorer using Apache Spark for Azure Synapse Analytics.
This topic describes how to install and configure the Azure Data Explorer Spark connector and move data between Azure Data Explorer and Apache Spark clusters.
Note
Although some of the examples below refer to an Azure Databricks Spark cluster, Azure Data Explorer Spark connector does not take direct dependencies on Databricks or any other Spark distribution.
Prerequisites
- An Azure subscription. Create a free Azure account.
- An Azure Data Explorer cluster and database. Create a cluster and database.
- A Spark cluster
- Install Azure Data Explorer connector library:
- Pre-built libraries for Spark 2.4+Scala 2.11 or Spark 3+scala 2.12
- Maven repo
- Maven 3.x installed
Tip
Spark 2.3.x versions are also supported, but may require some changes in pom.xml dependencies.
How to build the Spark connector
Starting version 2.3.0 we introduce new artifact Ids replacing spark-kusto-connector: kusto-spark_3.0_2.12 targeting Spark 3.x and Scala 2.12 and kusto-spark_2.4_2.11 targeting Spark 2.4.x and scala 2.11.
Note
Versions prior to 2.5.1 do not work anymore for ingest to an existing table, please update to a later version. This step is optional. If you are using pre-built libraries, for example, Maven, see Spark cluster setup.
Build prerequisites
If you are not using pre-built libraries, you need to install the libraries listed in dependencies including the following Kusto Java SDK libraries. To find the right version to install, look in the relevant release's pom:
Refer to this source for building the Spark Connector.
For Scala/Java applications using Maven project definitions, link your application with the following artifact (latest version may differ):
<dependency> <groupId>com.microsoft.azure</groupId> <artifactId>kusto-spark_3.0_2.12</artifactId> <version>2.5.1</version> </dependency>
Build commands
To build jar and run all tests:
mvn clean package
To build jar, run all tests, and install jar to your local Maven repository:
mvn clean install
For more information, see connector usage.
Spark cluster setup
Note
It's recommended to use the latest Azure Data Explorer Spark connector release when performing the following steps.
Configure the following Spark cluster settings, based on Azure Databricks cluster using Spark 2.4.4 and Scala 2.11 or Spark 3.0.1 and Scala 2.12:
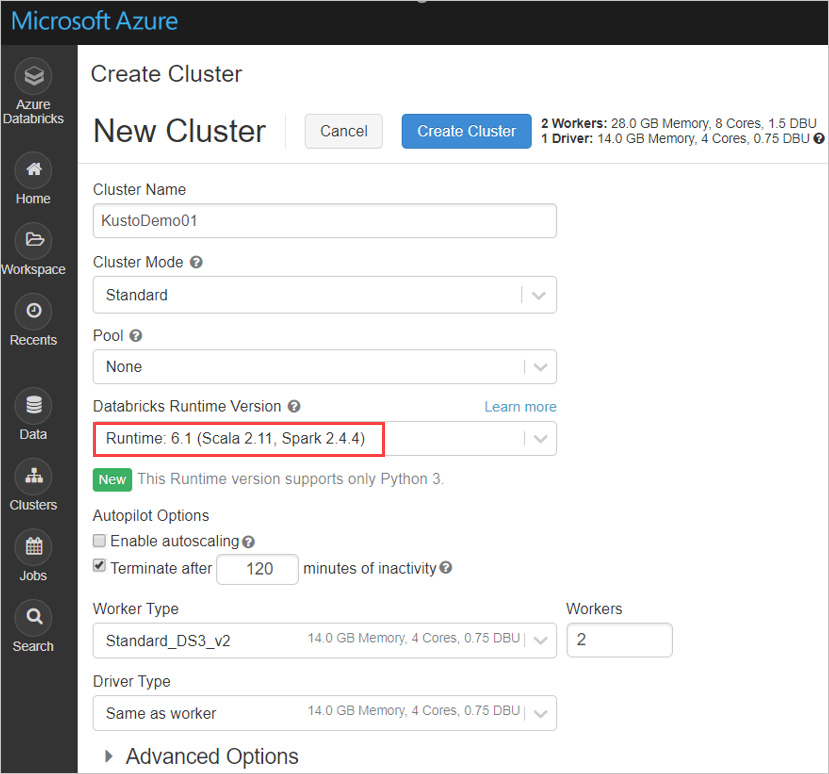
Install the latest spark-kusto-connector library from Maven:
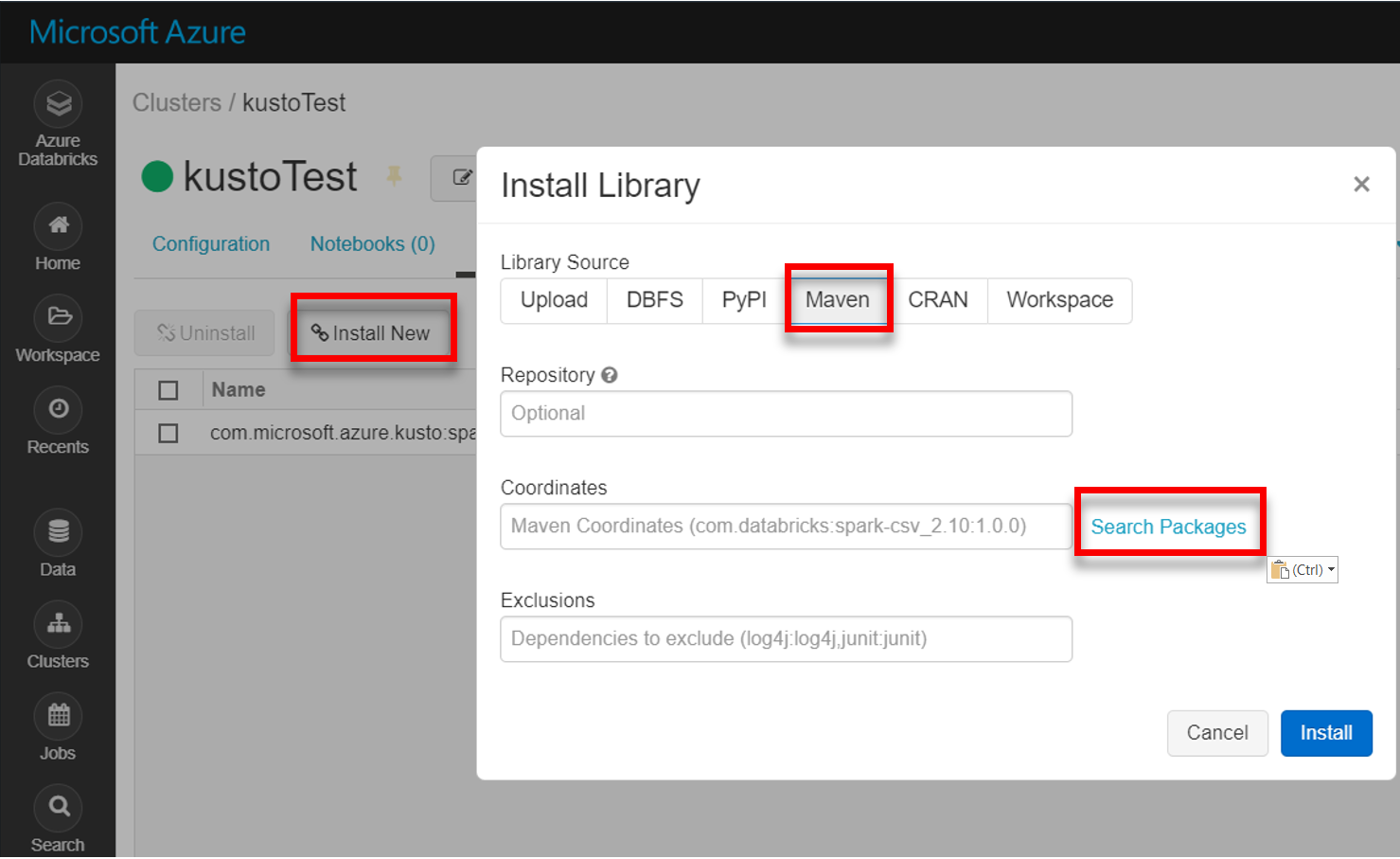
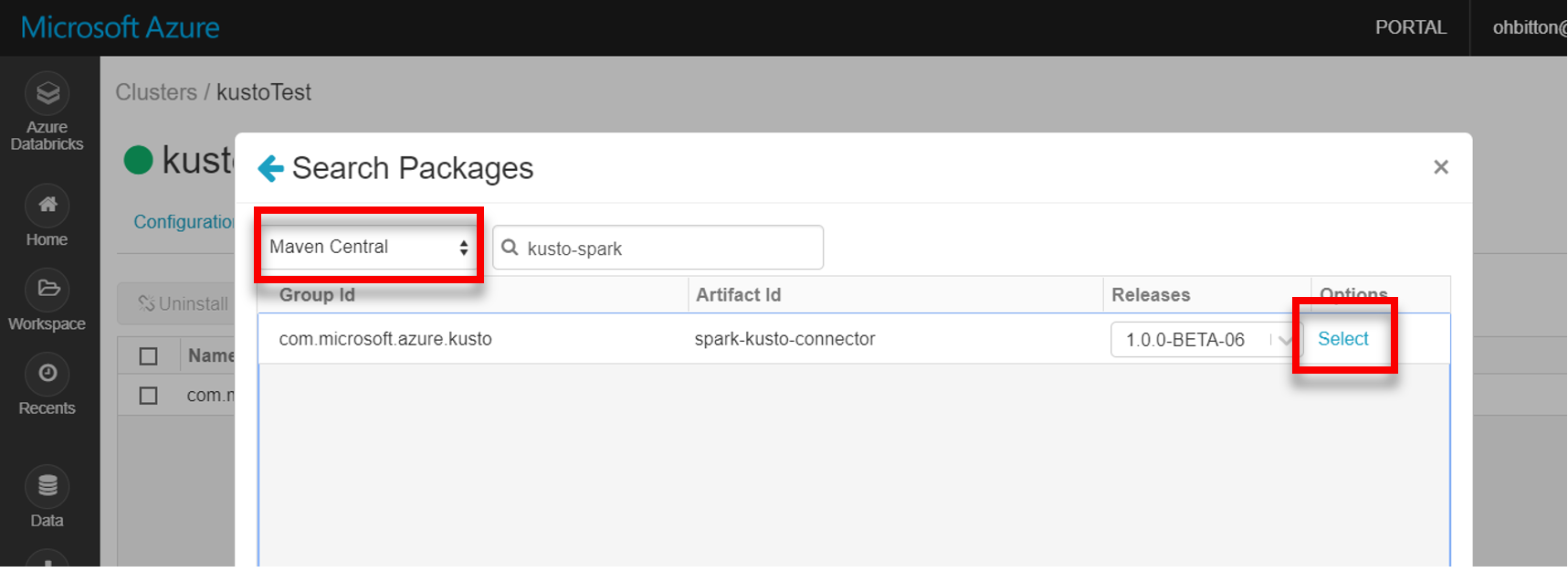
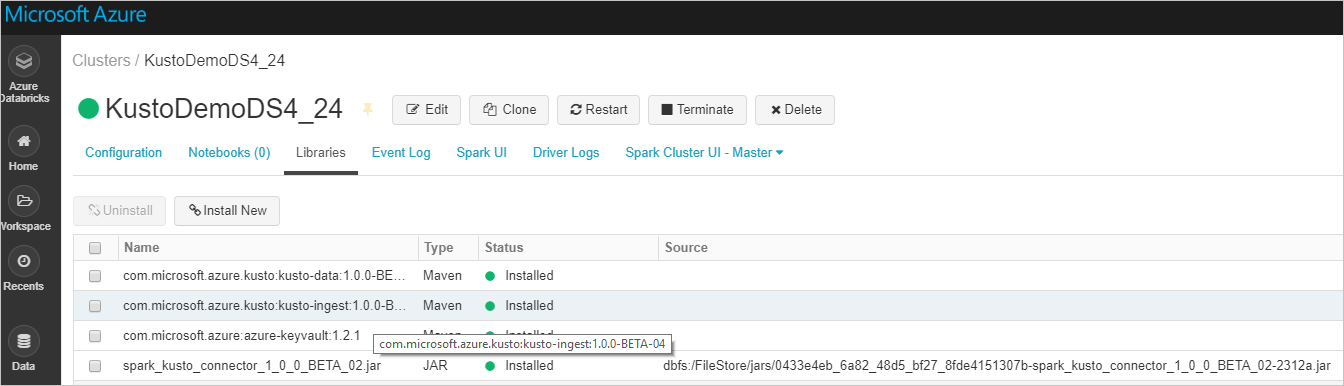
Verify that all required libraries are installed:
For installation using a JAR file, verify that additional dependencies were installed:
Authentication
Azure Data Explorer Spark connector enables you to authenticate with Microsoft Entra ID using one of the following methods:
- An Microsoft Entra application
- An Microsoft Entra access token
- Device authentication (for non-production scenarios)
- An Azure Key Vault To access the Key Vault resource, install the azure-keyvault package and provide application credentials.
Microsoft Entra application authentication
Microsoft Entra application authentication is the simplest and most common authentication method and is recommended for the Azure Data Explorer Spark connector.
| Properties | Option String | Description |
|---|---|---|
| KUSTO_AAD_APP_ID | kustoAadAppId | Microsoft Entra application (client) identifier. |
| KUSTO_AAD_AUTHORITY_ID | kustoAadAuthorityID | Microsoft Entra authentication authority. Microsoft Entra Directory (tenant) ID. Optional - defaults to microsoft.com. For more information, see Microsoft Entra authority. |
| KUSTO_AAD_APP_SECRET | kustoAadAppSecret | Microsoft Entra application key for the client. |
Note
Older API versions (less than 2.0.0) have the following naming: "kustoAADClientID", "kustoClientAADClientPassword", "kustoAADAuthorityID"
Azure Data Explorer privileges
Grant the following privileges on an Azure Data Explorer cluster:
- For reading (data source), the Microsoft Entra identity must have viewer privileges on the target database, or admin privileges on the target table.
- For writing (data sink), the Microsoft Entra identity must have ingestor privileges on the target database. It must also have user privileges on the target database to create new tables. If the target table already exists, you must configure admin privileges on the target table.
For more information on Azure Data Explorer principal roles, see role-based access control. For managing security roles, see security roles management.
Spark sink: writing to Azure Data Explorer
Set up sink parameters:
val KustoSparkTestAppId = dbutils.secrets.get(scope = "KustoDemos", key = "KustoSparkTestAppId") val KustoSparkTestAppKey = dbutils.secrets.get(scope = "KustoDemos", key = "KustoSparkTestAppKey") val appId = KustoSparkTestAppId val appKey = KustoSparkTestAppKey val authorityId = "72f988bf-86f1-41af-91ab-2d7cd011db47" // Optional - defaults to microsoft.com val cluster = "Sparktest.eastus2" val database = "TestDb" val table = "StringAndIntTable"Write Spark DataFrame to Azure Data Explorer cluster as batch:
import com.microsoft.kusto.spark.datasink.KustoSinkOptions import org.apache.spark.sql.{SaveMode, SparkSession} df.write .format("com.microsoft.kusto.spark.datasource") .option(KustoSinkOptions.KUSTO_CLUSTER, cluster) .option(KustoSinkOptions.KUSTO_DATABASE, database) .option(KustoSinkOptions.KUSTO_TABLE, "Demo3_spark") .option(KustoSinkOptions.KUSTO_AAD_APP_ID, appId) .option(KustoSinkOptions.KUSTO_AAD_APP_SECRET, appKey) .option(KustoSinkOptions.KUSTO_AAD_AUTHORITY_ID, authorityId) .option(KustoSinkOptions.KUSTO_TABLE_CREATE_OPTIONS, "CreateIfNotExist") .mode(SaveMode.Append) .save()Or use the simplified syntax:
import com.microsoft.kusto.spark.datasink.SparkIngestionProperties import com.microsoft.kusto.spark.sql.extension.SparkExtension._ val sparkIngestionProperties = Some(new SparkIngestionProperties()) // Optional, use None if not needed df.write.kusto(cluster, database, table, conf, sparkIngestionProperties)Write streaming data:
import org.apache.spark.sql.streaming.Trigger import java.util.concurrent.TimeUnit import java.util.concurrent.TimeUnit import org.apache.spark.sql.streaming.Trigger // Set up a checkpoint and disable codeGen. spark.conf.set("spark.sql.streaming.checkpointLocation", "/FileStore/temp/checkpoint") // Write to a Kusto table from a streaming source val kustoQ = df .writeStream .format("com.microsoft.kusto.spark.datasink.KustoSinkProvider") .options(conf) .trigger(Trigger.ProcessingTime(TimeUnit.SECONDS.toMillis(10))) // Sync this with the ingestionBatching policy of the database .start()
Spark source: reading from Azure Data Explorer
When reading small amounts of data, define the data query:
import com.microsoft.kusto.spark.datasource.KustoSourceOptions import org.apache.spark.SparkConf import org.apache.spark.sql._ import com.microsoft.azure.kusto.data.ClientRequestProperties val query = s"$table | where (ColB % 1000 == 0) | distinct ColA" val conf: Map[String, String] = Map( KustoSourceOptions.KUSTO_AAD_APP_ID -> appId, KustoSourceOptions.KUSTO_AAD_APP_SECRET -> appKey ) val df = spark.read.format("com.microsoft.kusto.spark.datasource"). options(conf). option(KustoSourceOptions.KUSTO_QUERY, query). option(KustoSourceOptions.KUSTO_DATABASE, database). option(KustoSourceOptions.KUSTO_CLUSTER, cluster). load() // Simplified syntax flavor import com.microsoft.kusto.spark.sql.extension.SparkExtension._ val cpr: Option[ClientRequestProperties] = None // Optional val df2 = spark.read.kusto(cluster, database, query, conf, cpr) display(df2)Optional: If you provide the transient blob storage (and not Azure Data Explorer) the blobs are created under the caller's responsibility. This includes provisioning the storage, rotating access keys, and deleting transient artifacts. The KustoBlobStorageUtils module contains helper functions for deleting blobs based on either account and container coordinates and account credentials, or a full SAS URL with write, read, and list permissions. When the corresponding RDD is no longer needed, each transaction stores transient blob artifacts in a separate directory. This directory is captured as part of read-transaction information logs reported on the Spark Driver node.
// Use either container/account-key/account name, or container SaS val container = dbutils.secrets.get(scope = "KustoDemos", key = "blobContainer") val storageAccountKey = dbutils.secrets.get(scope = "KustoDemos", key = "blobStorageAccountKey") val storageAccountName = dbutils.secrets.get(scope = "KustoDemos", key = "blobStorageAccountName") // val storageSas = dbutils.secrets.get(scope = "KustoDemos", key = "blobStorageSasUrl")In the example above, the Key Vault isn't accessed using the connector interface; a simpler method of using the Databricks secrets is used.
Read from Azure Data Explorer.
If you provide the transient blob storage, read from Azure Data Explorer as follows:
val conf3 = Map( KustoSourceOptions.KUSTO_AAD_APP_ID -> appId, KustoSourceOptions.KUSTO_AAD_APP_SECRET -> appKey KustoSourceOptions.KUSTO_BLOB_STORAGE_SAS_URL -> storageSas) val df2 = spark.read.kusto(cluster, database, "ReallyBigTable", conf3) val dfFiltered = df2 .where(df2.col("ColA").startsWith("row-2")) .filter("ColB > 12") .filter("ColB <= 21") .select("ColA") display(dfFiltered)If Azure Data Explorer provides the transient blob storage, read from Azure Data Explorer as follows:
val conf3 = Map( KustoSourceOptions.KUSTO_AAD_CLIENT_ID -> appId, KustoSourceOptions.KUSTO_AAD_CLIENT_PASSWORD -> appKey) val df2 = spark.read.kusto(cluster, database, "ReallyBigTable", conf3) val dfFiltered = df2 .where(df2.col("ColA").startsWith("row-2")) .filter("ColB > 12") .filter("ColB <= 21") .select("ColA") display(dfFiltered)
Related content
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for