What is Trino? (Preview)
Important
This feature is currently in preview. The Supplemental Terms of Use for Microsoft Azure Previews include more legal terms that apply to Azure features that are in beta, in preview, or otherwise not yet released into general availability. For information about this specific preview, see Azure HDInsight on AKS preview information. For questions or feature suggestions, please submit a request on AskHDInsight with the details and follow us for more updates on Azure HDInsight Community.
Trino (formerly PrestoSQL) is an open-source distributed SQL query engine for federated and interactive analytics against heterogeneous data sources. It can query data at scale (gigabytes to petabytes) from multiple sources to enable enterprise-wide analytics.
Trino is used for a wide range of analytical use cases and is an excellent choice for interactive and ad-hoc querying.
Some of the key features that Trino offers -
- An adaptive multi-tenant system capable of concurrently running hundreds of memory, I/O, and CPU-intensive queries, and scaling to thousands of worker nodes while efficiently utilizing cluster resources.
- Extensible and federated design to reduce the complexity of integrating multiple systems.
- High performance, with several key related features and optimizations.
- Fully compatible with Hadoop ecosystem.
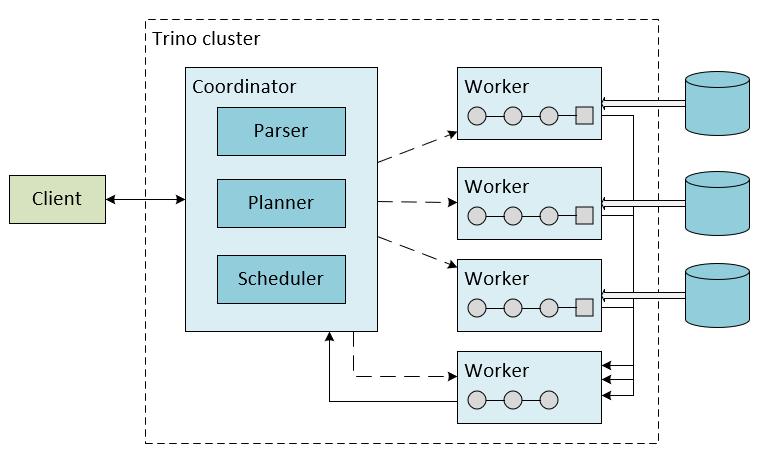
There are two types of Trino servers: coordinators and workers.
Coordinator
The Trino coordinator is the server that is responsible for parsing statements, planning queries, and managing Trino worker nodes. It's the “brain” of a Trino installation and is also the node to which a client connects to submit statements for execution. The coordinator keeps track of the activity on each worker and coordinates the execution of a query. The coordinator creates a logical model of a query, which involves a series of stages, which is translated into a series of connected tasks runs on a cluster of Trino workers.
Worker
A Trino worker is a server in a Trino installation, which is responsible for executing tasks and processing data. Worker nodes fetch data from connectors and exchange intermediate data with each other. The coordinator is responsible for fetching results from the workers and returning the final results to the client.
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for