How to use Flink/Delta Connector
Important
This feature is currently in preview. The Supplemental Terms of Use for Microsoft Azure Previews include more legal terms that apply to Azure features that are in beta, in preview, or otherwise not yet released into general availability. For information about this specific preview, see Azure HDInsight on AKS preview information. For questions or feature suggestions, please submit a request on AskHDInsight with the details and follow us for more updates on Azure HDInsight Community.
By using Apache Flink and Delta Lake together, you can create a reliable and scalable data lakehouse architecture. The Flink/Delta Connector allows you to write data to Delta tables with ACID transactions and exactly once processing. It means that your data streams are consistent and error-free, even if you restart your Flink pipeline from a checkpoint. The Flink/Delta Connector ensures that your data isn't lost or duplicated, and that it matches the Flink semantics.
In this article, you learn how to use Flink-Delta connector.
- Read the data from the delta table.
- Write the data to a delta table.
- Query it in Power BI.
What is Flink/Delta connector
Flink/Delta Connector is a JVM library to read and write data from Apache Flink applications to Delta tables utilizing the Delta Standalone JVM library. The connector provides exactly once delivery guarantees.
Flink/Delta Connector includes:
DeltaSink for writing data from Apache Flink to a Delta table. DeltaSource for reading Delta tables using Apache Flink.
Apache Flink-Delta Connector includes:
Depending on the version of the connector you can use it with following Apache Flink versions:
Connector's version Flink's version
0.4.x (Sink Only) 1.12.0 <= X <= 1.14.5
0.5.0 1.13.0 <= X <= 1.13.6
0.6.0 X >= 1.15.3
0.7.0 X >= 1.16.1 --- We use this in Flink 1.17.0
For more information, see Flink/Delta Connector.
Prerequisites
- HDInsight Flink 1.17.0 cluster on AKS
- Flink-Delta Connector 0.7.0
- Use MSI to access ADLS Gen2
- IntelliJ for development
Read data from delta table
Delta Source can work in one of two modes, described as follows.
Bounded Mode Suitable for batch jobs, where we want to read content of Delta table for specific table version only. Create a source of this mode using the DeltaSource.forBoundedRowData API.
Continuous Mode Suitable for streaming jobs, where we want to continuously check the Delta table for new changes and versions. Create a source of this mode using the DeltaSource.forContinuousRowData API.
Example: Source creation for Delta table, to read all columns in bounded mode. Suitable for batch jobs. This example loads the latest table version.
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.core.fs.Path;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.data.RowData;
import org.apache.hadoop.conf.Configuration;
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// Define the source Delta table path
String deltaTablePath_source = "abfss://container@account_name.dfs.core.windows.net/data/testdelta";
// Create a bounded Delta source for all columns
DataStream<RowData> deltaStream = createBoundedDeltaSourceAllColumns(env, deltaTablePath_source);
public static DataStream<RowData> createBoundedDeltaSourceAllColumns(
StreamExecutionEnvironment env,
String deltaTablePath) {
DeltaSource<RowData> deltaSource = DeltaSource
.forBoundedRowData(
new Path(deltaTablePath),
new Configuration())
.build();
return env.fromSource(deltaSource, WatermarkStrategy.noWatermarks(), "delta-source");
}
For other continuous model example, see Data Source Modes.
Writing to Delta sink
Delta Sink currently exposes the following Flink metrics:

Sink creation for nonpartitioned tables
In this example, we show how to create a DeltaSink and plug it to an existing org.apache.flink.streaming.api.datastream.DataStream.
import io.delta.flink.sink.DeltaSink;
import org.apache.flink.core.fs.Path;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.table.data.RowData;
import org.apache.flink.table.types.logical.RowType;
import org.apache.hadoop.conf.Configuration;
// Define the sink Delta table path
String deltaTablePath_sink = "abfss://container@account_name.dfs.core.windows.net/data/testdelta_output";
// Define the source Delta table path
RowType rowType = RowType.of(
DataTypes.STRING().getLogicalType(), // Date
DataTypes.STRING().getLogicalType(), // Time
DataTypes.STRING().getLogicalType(), // TargetTemp
DataTypes.STRING().getLogicalType(), // ActualTemp
DataTypes.STRING().getLogicalType(), // System
DataTypes.STRING().getLogicalType(), // SystemAge
DataTypes.STRING().getLogicalType() // BuildingID
);
createDeltaSink(deltaStream, deltaTablePath_sink, rowType);
public static DataStream<RowData> createDeltaSink(
DataStream<RowData> stream,
String deltaTablePath,
RowType rowType) {
DeltaSink<RowData> deltaSink = DeltaSink
.forRowData(
new Path(deltaTablePath),
new Configuration(),
rowType)
.build();
stream.sinkTo(deltaSink);
return stream;
}
For other Sink creation example, see Data Sink Metrics.
Full code
Read data from a delta table and sink to another delta table.
package contoso.example;
import io.delta.flink.sink.DeltaSink;
import io.delta.flink.source.DeltaSource;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.core.fs.Path;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.DataTypes;
import org.apache.flink.table.data.RowData;
import org.apache.flink.table.types.logical.RowType;
import org.apache.hadoop.conf.Configuration;
public class DeltaSourceExample {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// Define the sink Delta table path
String deltaTablePath_sink = "abfss://container@account_name.dfs.core.windows.net/data/testdelta_output";
// Define the source Delta table path
String deltaTablePath_source = "abfss://container@account_name.dfs.core.windows.net/data/testdelta";
// Define the source Delta table path
RowType rowType = RowType.of(
DataTypes.STRING().getLogicalType(), // Date
DataTypes.STRING().getLogicalType(), // Time
DataTypes.STRING().getLogicalType(), // TargetTemp
DataTypes.STRING().getLogicalType(), // ActualTemp
DataTypes.STRING().getLogicalType(), // System
DataTypes.STRING().getLogicalType(), // SystemAge
DataTypes.STRING().getLogicalType() // BuildingID
);
// Create a bounded Delta source for all columns
DataStream<RowData> deltaStream = createBoundedDeltaSourceAllColumns(env, deltaTablePath_source);
createDeltaSink(deltaStream, deltaTablePath_sink, rowType);
// Execute the Flink job
env.execute("Delta datasource and sink Example");
}
public static DataStream<RowData> createBoundedDeltaSourceAllColumns(
StreamExecutionEnvironment env,
String deltaTablePath) {
DeltaSource<RowData> deltaSource = DeltaSource
.forBoundedRowData(
new Path(deltaTablePath),
new Configuration())
.build();
return env.fromSource(deltaSource, WatermarkStrategy.noWatermarks(), "delta-source");
}
public static DataStream<RowData> createDeltaSink(
DataStream<RowData> stream,
String deltaTablePath,
RowType rowType) {
DeltaSink<RowData> deltaSink = DeltaSink
.forRowData(
new Path(deltaTablePath),
new Configuration(),
rowType)
.build();
stream.sinkTo(deltaSink);
return stream;
}
}
Maven Pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>contoso.example</groupId>
<artifactId>FlinkDeltaDemo</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<flink.version>1.17.0</flink.version>
<java.version>1.8</java.version>
<scala.binary.version>2.12</scala.binary.version>
<hadoop-version>3.3.4</hadoop-version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-streaming-java -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-clients -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>io.delta</groupId>
<artifactId>delta-standalone_2.12</artifactId>
<version>3.0.0</version>
</dependency>
<dependency>
<groupId>io.delta</groupId>
<artifactId>delta-flink</artifactId>
<version>3.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-parquet</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop-version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-runtime</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.0.0</version>
<configuration>
<appendAssemblyId>false</appendAssemblyId>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
Package the jar and submit it to Flink cluster to run
Upload the jar to ABFS.

Pass the job jar information in AppMode cluster.

Note
Always enable
hadoop.classpath.enablewhile reading/writing to ADLS.Submit the cluster, you should be able to see the job in Flink UI.

Find Results in ADLS.





Power BI integration
Once the data is in delta sink, you can run the query in Power BI desktop and create a report.
Open the Power BI desktop to get the data using ADLS Gen2 connector.
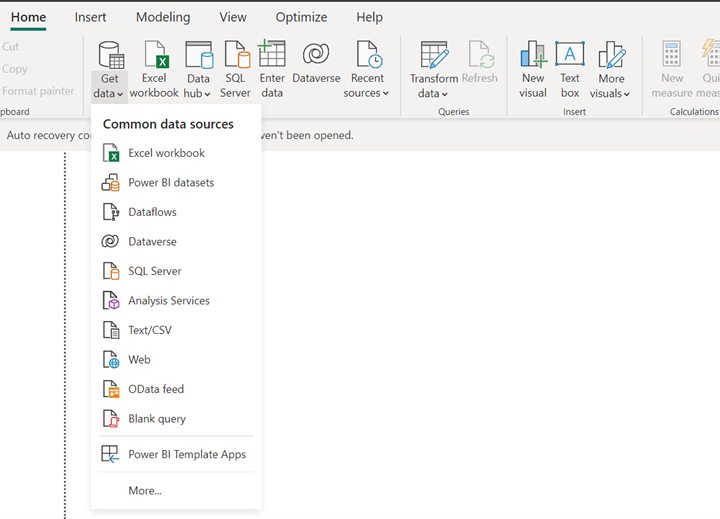
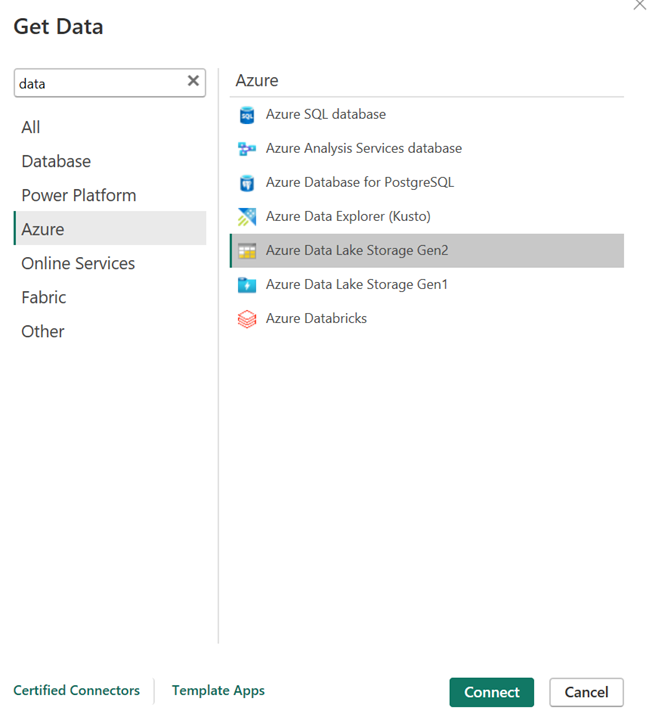
URL of the storage account.

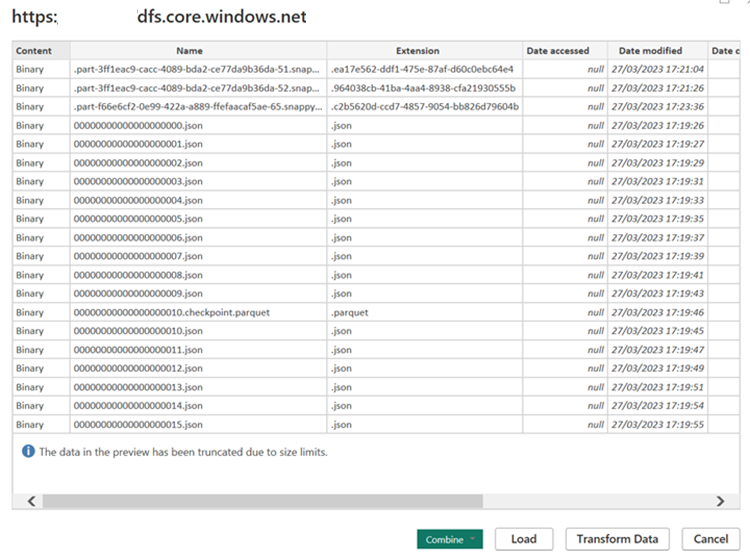
Create M-query for the source and invoke the function, which queries the data from storage account. Refer Delta Power BI connectors.
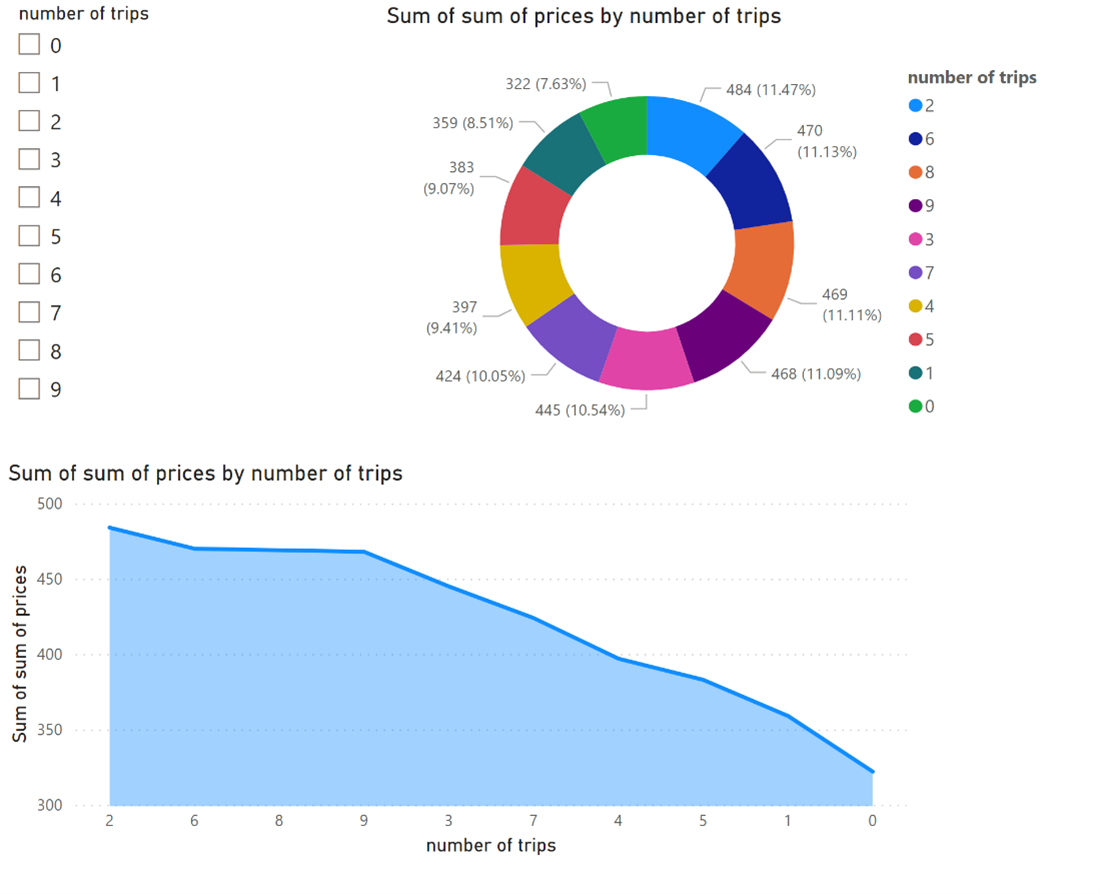
Once the data is readily available, you can create reports.
References
- Delta connectors.
- Delta Power BI connectors.
- Apache, Apache Flink, Flink, and associated open source project names are trademarks of the Apache Software Foundation (ASF).
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for